Why Enterprises Are Moving from Synapse to Databricks

As data volumes grow and analytics ambitions rise, enterprises are re-evaluating their data platforms. One noticeable trend? Many organizations are considering a move from Azure Synapse Analytics to Databricks.
The reason is clear: businesses want a platform that can scale, learn, and adapt with them. Whether it’s the need for more scalable processing, better ML integration, or a preference for open formats and Spark-native architecture, Databricks offers compelling advantages.
We've seen this firsthand in our recent engagement with a global conglomerate spanning manufacturing, retail, and logistics. Facing performance bottlenecks and limited flexibility for their data science initiatives, they partnered with us to transition their growing analytics workloads to Databricks. A move that ultimately unlocked 4x faster query performance and a 30% drop in data processing costs.
But like any shift, the journey isn't always straightforward.
From Warehousing to Intelligence: Why the Shift?
Synapse offers strong integration with Microsoft tools and is a natural fit for companies deep in the Azure ecosystem. It’s great for traditional data warehousing and BI workloads, especially when users are SQL-centric and reliant on Power BI.
But modern use cases are more complex, requiring machine learning, real-time analytics, unstructured and semi-structured data processing, and multi-cloud flexibility. Here’s where Synapse can feel limiting, especially when dealing with massive, fast-moving datasets or trying to implement end-to-end ML pipelines.
- Limited support for real-time processing and IoT-scale data ingestion, making it less suitable for dynamic, high-velocity environments.
- Manual scaling leads to inefficiencies and higher infrastructure costs, especially under unpredictable or bigger workloads.
- Handling semi-structured data (like JSON or Parquet) can be clunky, reducing agility for data science use cases.
- IoT and edge integrations are limited, restricting applicability in sensor-heavy or operations-driven industries.
- Lack of native support for end-to-end ML workflows often requires multiple tools stitched together, increasing complexity and maintenance overhead.
While Synapse serves well in static, structured BI environments, it struggles to meet the agility, scalability, and intelligence demands of modern data-driven enterprises. This was exactly the case with our client. As their ambitions expanded into real-time inventory forecasting, dynamic price optimization, and ML-driven logistics routing, Synapse became a bottleneck. Latency in data availability was slowing the data science teams who were increasingly frustrated by the lack of flexibility.
By moving their workloads to Databricks, and leveraging our Synapse to Databricks Migration Toolkit, the client was able to boost query performance by 4x, cut data processing costs by 30%, and enable machine learning pipelines to run in minutes rather than hours.
Databricks offers an open, unified platform built on Apache Spark, designed for scale, flexibility, and innovation. Whether it’s running notebooks, training models, or versioning data with Delta Lake, Databricks gives data teams the freedom to build.

Making the shift | What Makes It So Complicated?
Migrating from Synapse to Databricks isn’t a simple lift-and-shift job. The differences in architecture, governance, orchestration, and development practices require careful planning and technical nuance. Consider it a multidimensional migration, one that touches architecture, code, security, and people.
Migration Complexities
- Semantic Layer Rebuild: Business logic and views built in T-SQL must be redesigned using Databricks SQL or PySpark.
- Power BI Realignment: All Power BI datasets must be repointed to Databricks SQL endpoints; row-level security rules need to be redefined.
- Pipeline Reengineering: GUI-based Synapse/ADF pipelines require reimplementation in PySpark notebooks and Databricks Workflows.
- Governance Overhaul: Access controls, tags, and data lineage must be redefined in Unity Catalog to maintain enterprise-grade compliance.
- Performance Retuning: Optimizations like materialized views and caching need replacement with Delta Lake techniques (Z-Ordering, OPTIMIZE).
- DevOps Realignment: Existing CI/CD, monitoring, and deployment tooling needs to shift to Databricks-native tools and APIs.
- Skills Uplift: Teams need to transition from SQL-first to Spark- and code-first development, including governance and orchestration practices.
Native Mitigation Strategies with Databricks
The good news? Most of these challenges can be elegantly solved with Databricks-native features. And where needed, third-party tools like Airflow or Terraform complement the ecosystem.
Syren brings a flexible approach to your migrations. Whether your organization prefers native simplicity or wants to integrate external orchestration or deployment systems, we can design a solution around your preferences. (And yes, if we’re helping with your supply chain transformation, we’re also enabling your data platform future.)
- Use Databricks SQL Warehouse as the semantic layer to support BI workloads with enterprise concurrency and cost controls.
- Rebuild ETL and orchestration using PySpark notebooks and Databricks Workflows for flexibility and modularity.
- Govern access and data classification using Unity Catalog’s built-in RBAC, tags, and automated lineage tracking.
- Optimize performance and cost using Delta Lake capabilities—partitioning, caching, and automatic scaling of compute.
- Manage deployment and versioning through Databricks CLI, Repos, and Terraform (for infrastructure-as-code readiness).
- Enable operational monitoring using built-in job logging, alerts, and usage dashboards for governance and observability.
- Invest in skill enablement for Spark, Lakehouse principles, Unity Catalog, and notebook-based development across roles.
Synapse to Databricks Migration Tool Kit
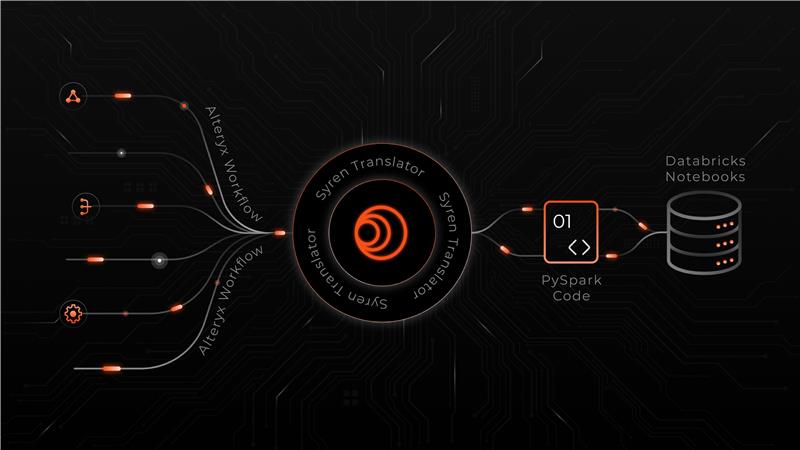
To take the heavy lifting out of this complex shift, we’ve built a Migration Toolkit, a modular, accelerator-backed framework that reduces manual effort, increases consistency, and speeds up time-to-value.
Here's how it works
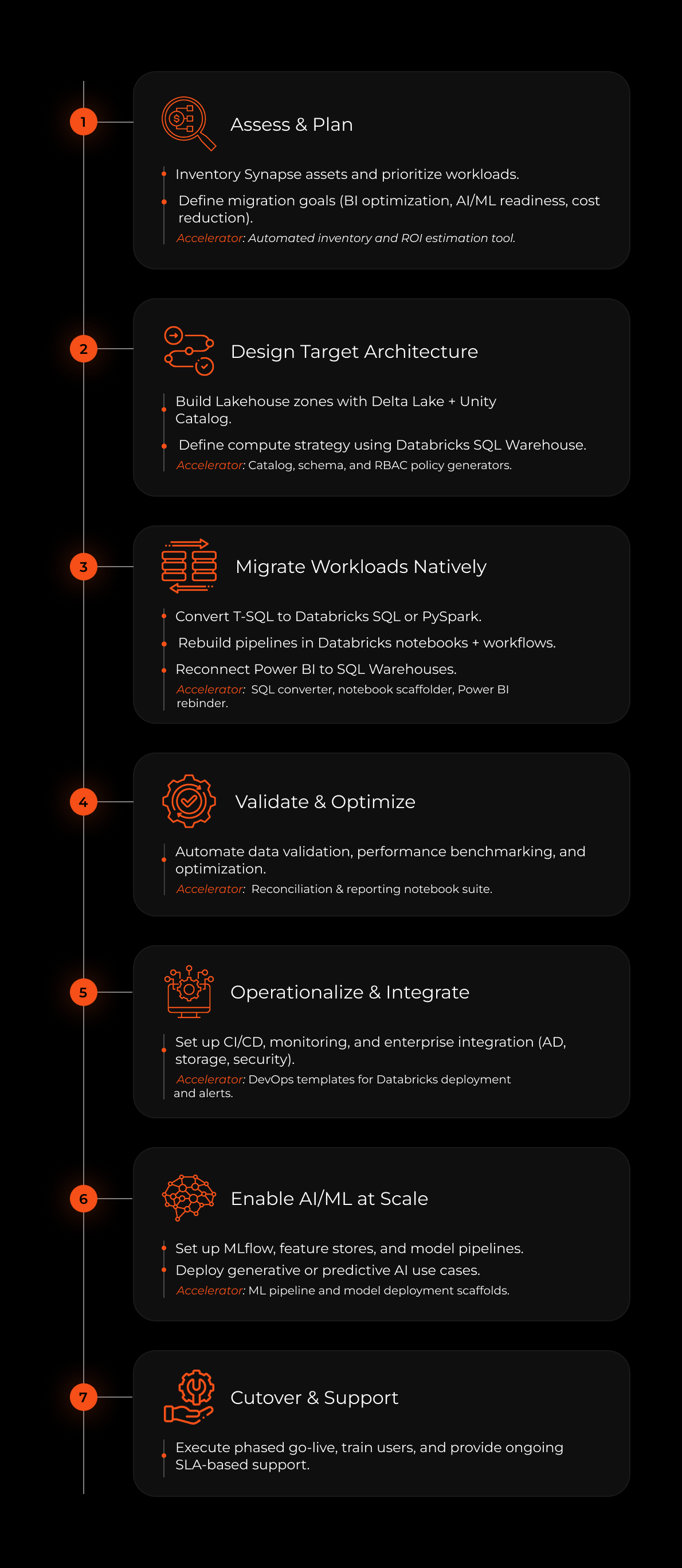
By using this toolkit, we completed a conglomerate’s migration upto 50% faster than typical industry timelines, minimizing disruption and accelerating their time-to-value.
The Real-World Payoff
The results speak for themselves
- 4x faster query performance, even as data volumes grew.
- 30% reduction in data processing costs and accelerated time-to-insight.
- ML pipelines that previously took hours, completed in minutes.
- Cross-functional collaboration unlocked via a unified, notebook-native workspace.
- Improved governance and data versioning with Delta Lake.
- Developer productivity gains and operational efficiencies achieved.
In short, they moved from a fragmented analytics setup to a future-ready data platform that empowers experimentation, decision-making, and innovation.
Why Syren?
With the right strategy, tools, and expertise, enterprises can benefit from significant performance, cost, and innovation gains. As data powers the next generation of business models, those who invest in flexible, AI-ready platforms will lead the way.
In partnership with Databricks, and powered by our proprietary accelerators and automation toolkits, Syren’s Data Engineering Services fast-track digital transformation by eliminating complexity, reducing manual effort, and enabling scalable, intelligent data operations.