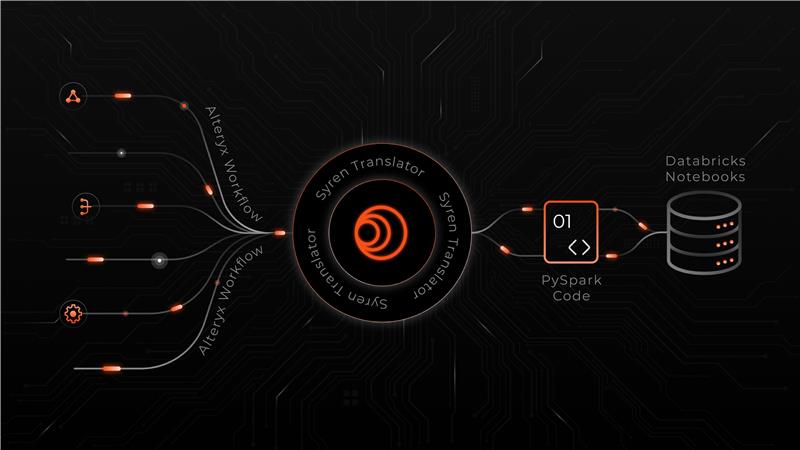
Alteryx has long served as a friendly, drag-and-drop interface for data teams. But for large enterprises chasing cloud scale, governance, and AI-readiness, what once felt fast is now slowing them down.
Syren’s client, a leading pharma company, was struggling with rising licensing costs and scattered Alteryx workflows spread across multiple business functions. This led to:
- Duplicate license costs
- No centralized version control
- No visibility into data lineage
- Long lead times for even minor changes
To counter these challenges, Syren built a translator to automatically parse Alteryx workflows and generate functionally equivalent Databricks Notebooks, turning a lengthy migration into a semi-automated modernization journey.
Why Manual Migration Doesn’t Work
Many Alteryx workflows contain dozens of transformation steps. Some span 7+ pages when printed out. Each one is built using proprietary tools that don't even map 1:1 to PySpark functions.
We estimated it would take a developer at least one week per workflow to rewrite and validate, totaling more than 20 developer-years, expensive and organizationally unfeasible.
How Syren Made the Migration Scalable?
Instead of taking a brute-force rewrite approach, which would have taken thousands of developer hours, Syren built a modular, semi-automated Alteryx-to-Databricks translator, a modular framework to analyze, interpret, and convert Alteryx workflows into executable Databricks notebooks with minimal manual effort. Apart from parsing and replicating existing workflows, the system was also designed to upgrade them for cloud-native execution, governance, and performance.
At its core, the translator performs six key components and functions:
Alteryx XML Reader
The Alteryx XML Reader is designed to parse XML files and convert them into structured, tabular data for use within Alteryx workflows. It leverages Alteryx’s Input Data Tool or the XML Parse Tool to extract specific elements from complex XML structures, making it easier to manipulate hierarchical data. Users can configure options such as selecting root or child elements, handling nested tags, and removing XML tag formatting to clean the output. For example, a typical use case might involve parsing a SEPA XML file that contains headers, payment information, and transaction details. However, when dealing with deeply nested XML structures, careful configuration of child element paths becomes critical. The tool is best suited for relatively simple XML schemas, as it lacks the flexibility needed for heavy-duty scripting or handling highly dynamic structures.
Topology Converter
This component transforms an Alteryx workflow’s XML into a Directed Acyclic Graph (DAG), visually representing the flow of data and dependencies between steps. By analyzing the metadata and connection information within the workflow XML, it generates a DAG image (such as a PNG) that illustrates how data moves and transforms through the system, without including tool names, keeping the focus on flow logic. This visual abstraction simplifies understanding of complex workflows and serves as a critical foundation for further translation into executable code such as PySpark. It bridges the gap between low-code platforms and scalable code-based execution environments.
Alteryx Tool Mapper & Rule Engine
The Tool Mapper and Rule Engine module is the heart of translating no-code Alteryx tools into executable PySpark transformations. It maps tools like Filter, Join, and Formula directly to PySpark DataFrame operations such as .filter() and .join(). Meanwhile, the Rule Engine handles the nuances of tool configuration—such as interpreting logical expressions or mathematical formulas. For example, an Alteryx Filter tool configured with the condition age > 30 would be translated into df.filter(df.age > 30) in PySpark. This mapping ensures consistency and accuracy during the transformation and allows for the automation of complex logic translation at scale.
PySpark Code Generator
Using the mapped DAG and transformation rules, the PySpark Code Generator produces clean, executable PySpark code. It begins with an input DataFrame and sequentially applies transformations in the correct order as determined by the DAG. Each step mirrors its corresponding Alteryx tool, ultimately producing a final DataFrame ready for output to a target destination, such as a file system or a database. This module bridges the no-code to code gap, enabling teams to deploy logic designed in Alteryx into scalable big data environments.
DataFrame Registry
During PySpark code generation, the DataFrame Registry tracks all intermediate DataFrames created throughout the workflow. This internal registry stores metadata such as schema information and data source identifiers, enabling transformations to reference and reuse previously generated DataFrames instead of recalculating them. For instance, if a join operation produces a DataFrame that is then filtered and aggregated further down the line, the registry ensures the original joined DataFrame is available when needed. This not only improves code readability and modularity but also reduces redundant computations, which significantly enhances performance.
Databricks Notebook Generator
The final step in the pipeline is the Databricks Notebook Generator, which packages the generated PySpark code into a ready-to-run notebook format compatible with Databricks. It embeds the transformation logic along with configurable elements like cluster settings, initialization scripts, and library dependencies—ensuring a seamless deployment experience. This integration enables teams to move effortlessly from Alteryx-based design to enterprise-grade execution on Databricks, unlocking the power of distributed processing and advanced analytics in cloud environments.
Syren’s GenAI Edge
Syren accelerated translation and reduced the development cycle by integrating Gen AI models into the pipeline. To ensure accuracy and business relevance, our developers validated the outputs, added context, and resolved inefficiencies.
Syren Recommendation
When approaching a transition from Alteryx to Databricks, it's essential to choose the right path based on your organization’s needs, timeline, and level of cloud maturity. Here’s what Syren recommends:
1. Choose Migration
Opt for migration if you have several workflows built in Alteryx that would be time-consuming to recreate from scratch. A migration approach, supported by Databricks, minimizes risks and allows you to leverage advanced tools like Unity Catalog for data governance. It also provides better scalability and unlocks the platform’s full potential for AI/ML capabilities.
2. Choose Building New Jobs
If you're starting from a clean slate or only have a few legacy workflows, consider allowing teams to fully embrace native Databricks features. This is ideal for future-ready, AI-driven projects with long-term scalability in mind.
3. Choose AI-Supported Migration
For teams looking to balance speed, accessibility, and scalability, an AI-supported migration offers a hybrid approach. By combining Alteryx Analytics Cloud with Databricks integration, organizations can accelerate workflow transitions. However, it’s important to validate AI-generated outputs, especially for complex, multi-step workflows, to ensure reliability and performance.
Each approach offers unique advantages. Syren helps clients evaluate their ecosystem and goals to determine the optimal path for their migration journey.
Business Impact
Even without uniform metrics across workflows, the results were clear:
- Time savings: Complex workflows that would’ve taken a week to rewrite were handled in hours.
- Faster development cycles: AI-assisted translation and reusable modules reduced coding time by 40–60%.
- Better governance: All workflows are now centralized, version-controlled, and auditable.
- Platform scale: The client now operates on Databricks, a modern, cloud-native data stack built for advanced analytics and AI.
Conclusion
This initiative was a transformation in how the enterprise approached ETL modernization.
By treating the translator as a reusable asset, Syren ensured that the future migrations from Alteryx or other legacy tools could be executed faster, with less friction. More importantly, the approach delivered immediate value, faster data readiness, tighter governance, and a foundation built for AI scale.
Like this Fortune 500 Pharma leader, Syren can power your next wave of transformation, too!


