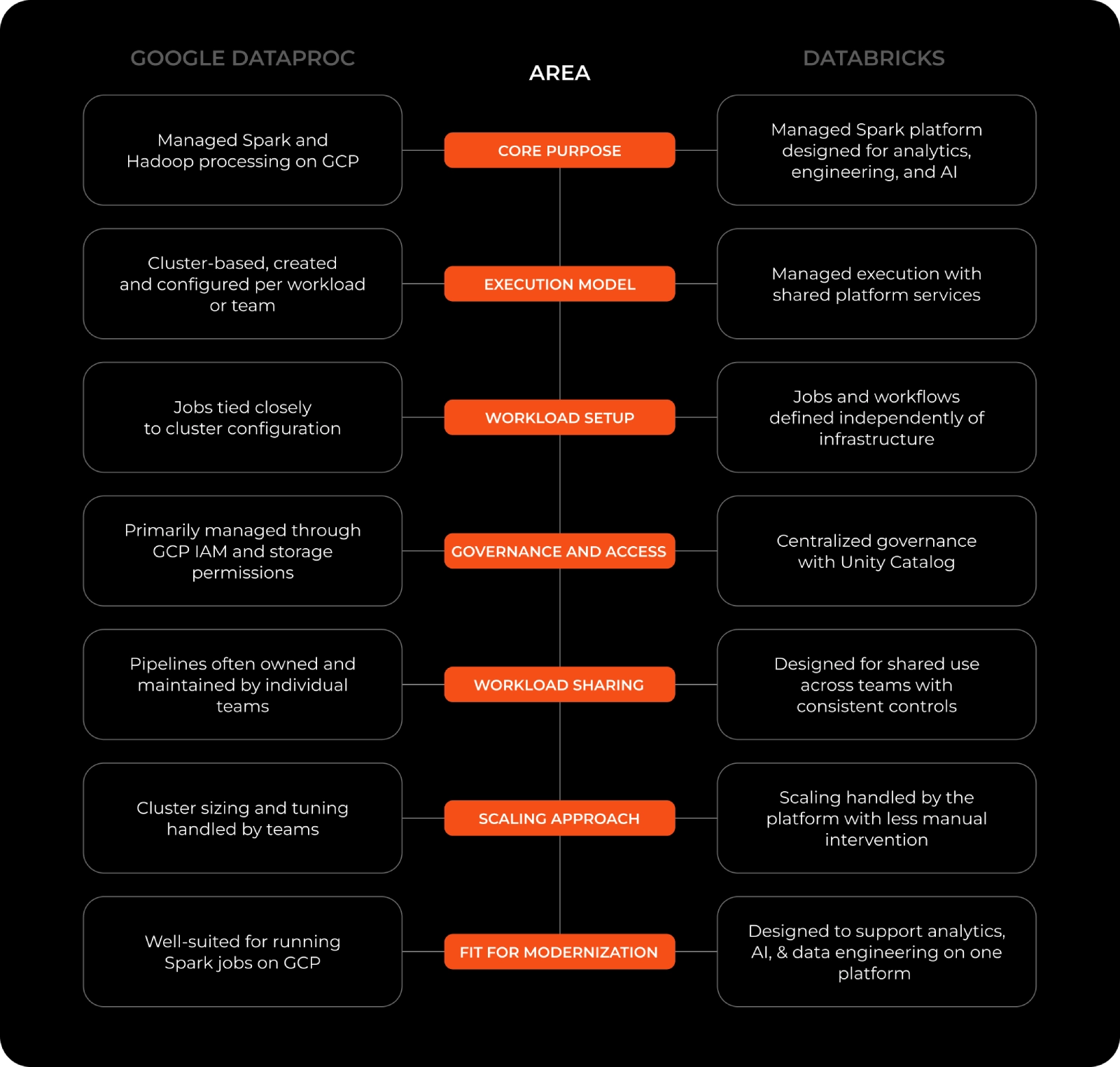
Many enterprises originally adopted Google Dataproc as part of their early cloud data engineering initiatives. The platform supports large-scale Spark and Hadoop processing and integrates closely with the broader GCP ecosystem. As usage expands across reporting, forecasting, machine learning, and operational analytics, Dataproc environments are extended beyond their original batch-processing use cases.
As data volumes increase and more teams rely on shared data, organizations begin assessing whether existing Dataproc environments can meet requirements around governance, scalability, and cross-team collaboration. In this context, dataproc to databricks migration is often evaluated as part of efforts to standardize analytics, governance, and data access across teams. Databricks is evaluated for its managed Lakehouse architecture, centralized governance capabilities, and ability to support analytics, data engineering, and AI workloads on a shared foundation while continuing to run Spark-based pipelines.
Migration planning at this stage focuses on building a clear view of existing Dataproc jobs, data pipelines, and supporting configurations. Teams also need to understand how current Spark and Hadoop workloads run when moved to a different platform with centralized governance and managed execution. This visibility helps organizations plan dataproc to databricks migration with realistic assumptions around effort, timelines, and operational impact.
This article outlines common challenges with Google Dataproc, key platform considerations when evaluating Databricks, and how Syren’s DP2Bricks accelerator supports organizations in approaching Dataproc to Databricks migration in a structured way.
What are the challenges faced by businesses in the Google Dataproc environment?
As Dataproc environments grow, teams often run Spark and Hadoop workloads across multiple clusters. These clusters are commonly configured for specific jobs or teams, leading to differences in settings, dependencies, and runtime behaviour. This directly leads to engineers spending more time managing clusters, tuning configurations, and resolving runtime issues rather than improving data pipelines and analytics delivery.
Dependency management is another common challenge in Dataproc environments. Many pipelines rely on custom JARs, third-party libraries, and job-specific settings that are maintained manually. Over time, this creates tight coupling between workloads and the clusters they run on, which slows updates, complicates troubleshooting, and makes platform changes difficult.
Defining the scope of Dataproc to Databricks migration is often difficult because Google Dataproc workloads vary widely in structure and ownership. Dataproc environments typically include a mix of batch and streaming jobs, different Spark languages, external dependencies, and multiple orchestration patterns. Security and access controls are also handled differently across teams. Without a consolidated view of these factors, migration from Dataproc relies on assumptions rather than evidence, which increases uncertainty around effort, sequencing, and operational impact.
Azure Databricks vs Google Dataproc
Why Shift to Databricks from Google Dataproc
Organizations begin exploring a shift from Google Dataproc to Databricks when existing environments become harder to scale consistently across teams. As pipelines, users, and data products grow, managing clusters, dependencies, and access becomes increasingly complex. Databricks excels in its ability to centralize execution, governance, and data access while continuing to support existing Spark and Hadoop workloads.
In many Dataproc environments, access controls, data definitions, and pipeline ownership are handled differently by each team, which limits shared visibility and makes it harder to enforce standards. Databricks is often considered because it provides a centralized way to manage data access, lineage, and usage across analytics and engineering workloads, helping organizations apply common controls while supporting broader data access.
Cost behaviour and scaling patterns also influence decisions to move away from Dataproc. As platform usage broadens, always-on clusters and repeated processing logic can make spend harder to predict. Teams with Databricks often want clearer insight into how workloads scale under different usage patterns and how compute usage aligns with actual demand. This makes early validation important, especially when organizations need to compare platforms using real pipelines rather than estimates.
DP2Bricks: Syren’s Dataproc to Databricks Migration Accelerator
Syren’s DP2Bricks is designed as a Databricks-native accelerator that helps streamline how organizations modernize Spark, Hadoop, and PySpark workloads from Dataproc to Databricks. It supports activities such as job inventorying, code conversion, dependency mapping, performance optimization, and validation, helping teams reduce manual effort during migration. The accelerator also incorporates incremental, test-driven validation using Delta Lake, allowing teams to compare outputs side by side and build confidence before moving workloads forward.
Built-in governance is an important part of this approach. DP2Bricks aligns migrated workloads with Unity Catalog, enabling consistent handling of data access, lineage, auditing, and security as pipelines move to Databricks. This allows organizations to modernize analytics while maintaining control and visibility across teams and data domains.
DP2Bricks helps organizations standardize Spark and Hadoop logic as workloads move to Databricks, reducing logic drift and improving consistency across downstream analytics. By consolidating fragmented Spark and Hadoop logic into standardized, Databricks-ready formats, teams reduce logic drift and improve consistency across reports, dashboards, and downstream analytics. This standardization supports a shared view of data across teams and helps create a reliable foundation for enterprise analytics.
The accelerator also supports faster platform adoption by enabling teams to validate Databricks performance, governance, and analytics capabilities using their existing workloads. By running representative production pipelines on Databricks, teams can evaluate performance, governance, and operational behaviour before expanding migration scope. This shortens evaluation cycles and helps teams move forward with clearer expectations around effort and outcomes.
DP2Bricks also helps teams gain early visibility into performance and cost behaviour as workloads move from Dataproc to Databricks. By identifying incompatible patterns, inefficient transformations, and non-portable configurations during migration, teams can better understand how pipelines perform under Databricks execution. This reduces runtime variability and supports more predictable compute usage as workloads scale.
As part of this process, organizations are able to evaluate Databricks using real pipelines rather than synthetic benchmarks. This makes it easier to compare performance characteristics, understand cost drivers, and plan capacity with greater confidence before committing to a large-scale Dataproc to Databricks migration.
Customer Success: Retail Data Platform Modernization with DP2Bricks
A large retail organization relied on Google Dataproc Spark and Hadoop jobs to support daily sales reporting, inventory forecasting, pricing analysis, and supply chain visibility. Over time, growing data volumes from stores, e-commerce channels, and loyalty programs placed pressure on the existing setup. Multiple Dataproc clusters with inconsistent configurations made SLA-critical jobs harder to manage, while repeated ETL logic and manual dependency updates increased delivery effort.
The organization used DP2Bricks to migrate a set of representative Dataproc pipelines to Databricks, including sales ETL workflows, pricing models, and inventory feeds. Workloads were converted and validated using real production data, with outputs compared side by side to ensure accuracy. Governance and data access were standardized across teams, providing clearer lineage and shared controls.
Outcomes
- 50–70% reduction in migration effort: Automated conversion and validation reduced the manual work required to move Dataproc Spark and Hadoop pipelines to Databricks.
- 30–60% improvement in pipeline performance: Early identification of inefficient patterns and platform-specific configurations led to more consistent runtime behavior.
- Lower ongoing effort to manage clusters and dependencies: Consolidation on Databricks reduced time spent on cluster maintenance, dependency updates, and troubleshooting.
- 2–4× faster onboarding of analytics and machine learning workloads: Validated pipelines provided a stable foundation for expanding analytics and ML use cases on Databricks.
A Practical Path Forward for Dataproc Modernization
Dataproc to Databricks migration is most effective when approached as a structured modernization effort rather than a one-time platform switch. Organizations benefit from starting with a clear view of existing Spark and Hadoop workloads, understanding dependencies and data flows, and validating how representative pipelines perform on Databricks before expanding the migration scope.
By assessing real workloads, validating outputs, and aligning governance through Unity Catalog, organizations can plan migration with clearer expectations around effort, performance, and cost behaviour. This approach supports steady progress while reducing disruption to business-critical analytics.
For enterprises modernizing their data platforms, this path provides a balance between speed and control. It is especially relevant for organizations operating in regulated or high-collaboration environments such as finance, healthcare, retail, or large multi-team analytics setups, where governance, access controls, and data lineage need to be planned early. By taking a measured approach, teams can adopt Databricks with confidence and scale Dataproc to Databricks migration across domains on a foundation that supports analytics, engineering, and AI workloads over time.


