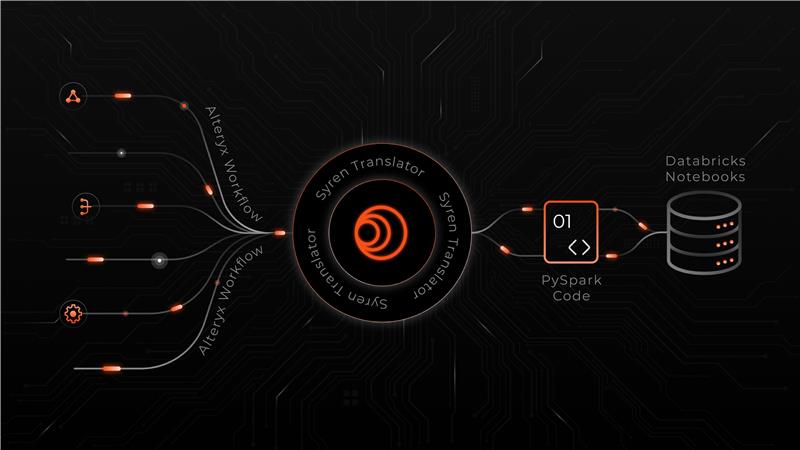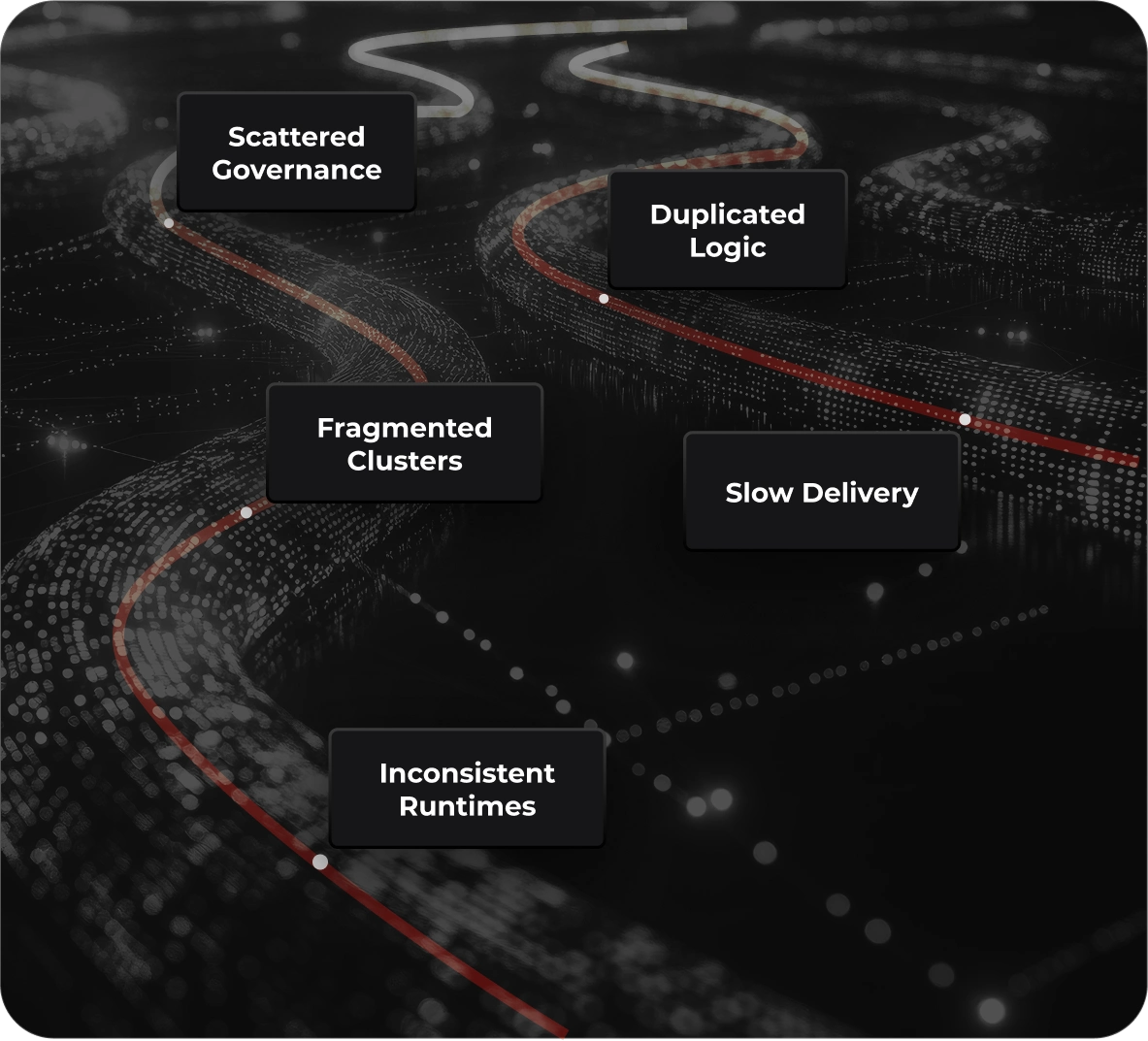

Fragmented clusters lead to limited cross-team visibility.

High operational overhead and pipeline maintenance.

Manual logic causes metric drift, slow reporting, and unreliable analytics.

Lack of unified governance and lineage makes scaling difficult.

Unable to estimate migration effort, cost, or timelines, blocking modernization planning.
 Spark Conversion & Optimization Engine
Spark Conversion & Optimization Engine
Transforms Dataproc Spark/Hive workloads into Databricks-ready formats, including Spark SQL rewrites, config normalization, Delta Lake adoption, and optimized cluster/job definitions.
 Workload Classification & Dependency Mapping
Workload Classification & Dependency Mapping
Maps dependencies across jobs, libraries, JARs, UDFs, Airflow/Dataproc Workflow templates, and cluster configs, highlighting incompatibilities and grouping workloads for staged migration.
 AI-Powered Intelligence
AI-Powered Intelligence
AI-driven insights to detect Spark anti-patterns, recommend efficient Databricks alternatives (Photon, Delta Lake, Auto-Optimize), and automatically fix common migration blockers.
 Performance Monitoring & Alerts
Performance Monitoring & Alerts
Near real-time visibility into migration readiness with automated detection of performance bottlenecks, deprecated APIs, non-portable configurations, and required optimizations.
 Data Governance
& Security
Data Governance
& Security
Unity Catalog ensures secure and compliant handling of notebooks, SQL logic, libraries, job configurations, and lineage during migration.
 Data Ingestion & Standardization
Data Ingestion & Standardization
Ingestion of Dataproc Spark jobs, PySpark notebooks, Hive SQL scripts, and workflow metadata into a normalized structure for automated analysis and migration planning.






Dataproc to Databricks Migration: A Practical Guide for Enterprise Data Teams




Syren + Databricks | GenAI Partner Solution OTIF-D for Healthcare & Life Sciences