1. What manufacturers keep telling us
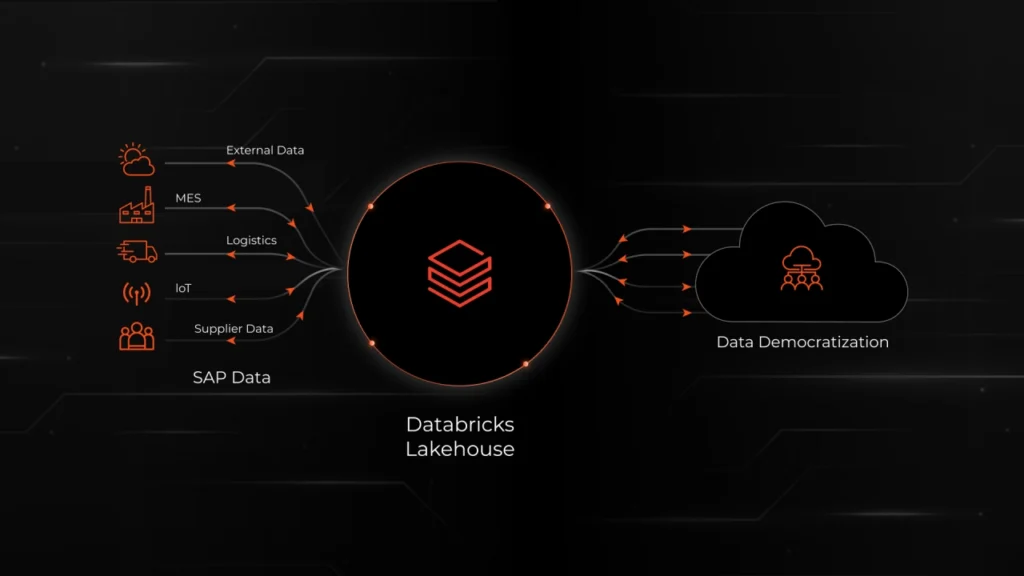
At Syren, we work primarily with manufacturing and supply chain enterprises, and we hear the same story almost everywhere we go. SAP runs the operational core of the business, production planning, materials management, logistics, finance, procurement, plant maintenance, and yet the people who most need that data to do their jobs cannot get to it.
The plant manager is waiting for a stockout report. The supply chain analyst is trying to model supplier risk against actual purchase order behavior. The finance partner is reconciling a close. The data science team is trying to build a demand forecast that combines SAP shipment history with weather, point-of-sale, and IoT signals from the shop floor.
Every one of those people ends up either filing a ticket with a central BW team, working from a stale Excel export, or building a shadow data pipeline on the side. None of those is sustainable, and none of them scales to the kind of AI-driven decisioning that manufacturers actually need to compete on now.
This raises a fair question: SAP has had analytics tools for thirty years BW, BEx, SAC, Datasphere, and now Business Data Cloud. Why not just use those?
SAP's analytics stack is genuinely good at what it was built for: structured, semantically rich, governed analysis of SAP data. For SAP-internal financial reporting, planning, and BI, it often is the right tool, and we would never recommend ripping it out.
But the workloads that define modern manufacturing and supply chain analytics look different. They combine SAP data with significant non-SAP data, MES output, IoT telemetry from the shop floor, supplier risk feeds, weather, point-of-sale, and logistics tracking. They use open-source ML frameworks and foundation models. They span structured, semi-structured, and unstructured data.
They demand a single platform across the whole data estate, not separate stacks for "SAP" and "everything else." The SAP analytics stack was never designed for this, and SAP itself acknowledged as much when it partnered with Databricks in February 2025 rather than trying to build a competing AI and ML platform.
So the question isn't "SAP tools or Databricks." It's: where does each set of workloads belong? SAP-internal analytics, planning, and governed financial reporting stay on the SAP stack where they belong. Cross-domain analytics, ML, AI, and the lakehouse that underpins them belong on Databricks. The work of democratizing SAP data is the work of getting trusted, semantically rich SAP data across that boundary cleanly without losing the business context that makes it trustworthy in the first place.
This is the problem we work on every day. Sitting at the intersection of manufacturing, supply chain, and Databricks gives us at Syren a vantage point that is relatively rare most SAP integrators don't go deep on the lakehouse side, and most Databricks practitioners don't have manufacturing process knowledge.
Combining those two perspectives is what lets us build solutions that actually democratize SAP data for the teams that need it, rather than just relocating a silo.
A lakehouse architecture is the cleanest answer the industry has produced for the cross-domain side of that boundary, and the SAP–Databricks partnership has made that answer dramatically more practical to implement. This article is about how to actually build that lakehouse what to plan for, what to avoid, and what trade-offs to defend in an architecture review.
2. What "democratizing SAP data" actually means
Three things have to be true at once, or you don't have democratization; you just have data movement.
- Reach. Anyone with a legitimate business need can discover, query, and analyze SAP data without a specialist team to assist. Marketing should be able to join customer master data with campaign performance. Supply chains should be able to combine purchase orders with IoT telemetry. Data scientists should be able to train models on SAP data alongside everything else.
- Trust. In the Age of LLMs trust is the most important metric, if you get a different response for same question every time, democratizing data is worthless. The data carries its business context with it. A field called KUNNR is meaningless to a marketing analyst; "Customer Number" with a description and a foreign-key relationship to the customer master is what they need. Definitions, lineage, and personal-data classifications travel with the data, not in a separate Confluence page that goes stale.
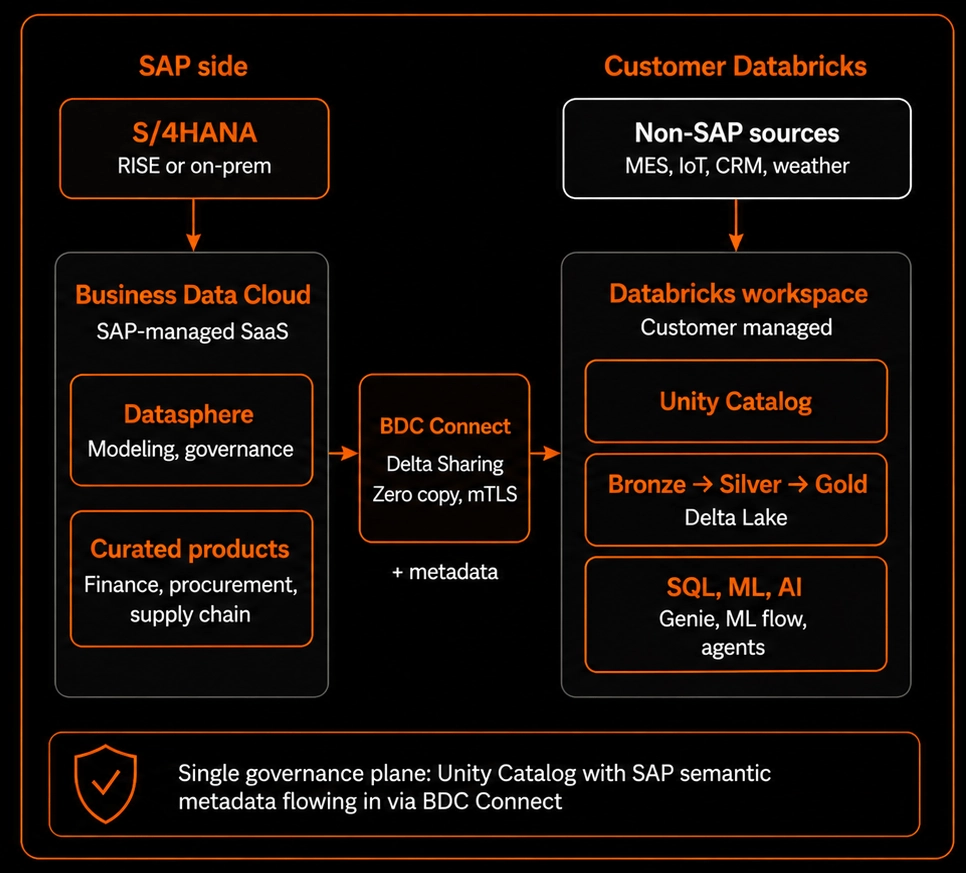
- Governance. Reach and trust without governance is how organizations end up with twelve definitions of "revenue." Unity Catalog (on the Databricks side) and SAP Business Data Cloud's governance layer (on the SAP side) need to agree on who can see what, with audit trails that satisfy both internal control and external regulators.
A lakehouse delivers all three when it's built correctly. Without thoughtful design, you get a fast data lake with SAP data dumped into it, which is the same data silo, just relocated.
3. The SAP source landscape
Before designing the Lakehouse, you need an honest inventory of what "SAP" actually means in your estate. This shapes every downstream choice, and it is foundational to any serious SAP data management strategy.
3.1 SAP ECC (typically ECC 6.0)
Still the most widely deployed SAP ERP. Runs on Oracle, Db2, SQL Server, or HANA. Mainstream maintenance ends December 2027, which is the single biggest driver of S/4HANA migration projects in flight today. Integration realities:
- No CDS views. Extraction relies on classic SAPI ("S-API") extractors, raw tables (including pool and cluster tables), BAPIs/RFCs, or IDocs.
- Delta extraction is harder. Many ECC sources lack clean primary keys, complicating CDC. This is why SAP recommends BW Bridge as the staging layer when ECC feeds the Datasphere.
- Database matters. ECC on HANA with BASIS ≥ 7.4 opens up significantly more integration options than ECC on a classic RDBMS.
3.2 SAP S/4HANA: three deployment models, three integration profiles
- S/4HANA on-premise, Full extraction surface: tables, CDS views (including CDC-enabled extraction-ready CDS views), released SAPI extractors.
- S/4HANA Cloud, private edition (RISE with SAP), same logical surface as on-prem but hyperscaler-hosted with networking constraints. Note that SAP BDC was initially offered only to RISE / private cloud S/4HANA customers, with broader support added subsequently.
- S/4HANA Cloud, public edition, no SAPI extractors at all. Integration goes through public APIs, OData services on CDS views, and SAP-managed integration content.
The strategic modernization here is extraction-enabled (and CDC-enabled) CDS views plus the ODP framework, replacing the old RSA7 / BW Delta Queue model.
3.3 SAP BW and BW/4HANA
The classic SAP analytical warehouse and its HANA-native successor. Holds modeled, harmonized data (InfoProviders, aDSOs, CompositeProviders) rather than raw transactions. Often a better source for the Lakehouse than raw ECC tables, because the business modeling work is already done. BW Bridge inside the Datasphere is the recommended path for BW customers transitioning to the BDC world.
3.4 SAP HANA as a database
HANA appears in two roles: as the underlying DB for S/4HANA / BW4HANA (integrate at the application layer, not here), and as a standalone HANA Cloud / HANA sidecar running calculation views for analytics. JDBC integration to HANA is straightforward but comes with source-load and licensing caveats.
3.5 SAP Datasphere
SAP's cloud data fabric. Connects, models, federates, and governs data across SAP and non-SAP sources. Now the engine that powers SAP's recommended integration paths, including Replication Flows.
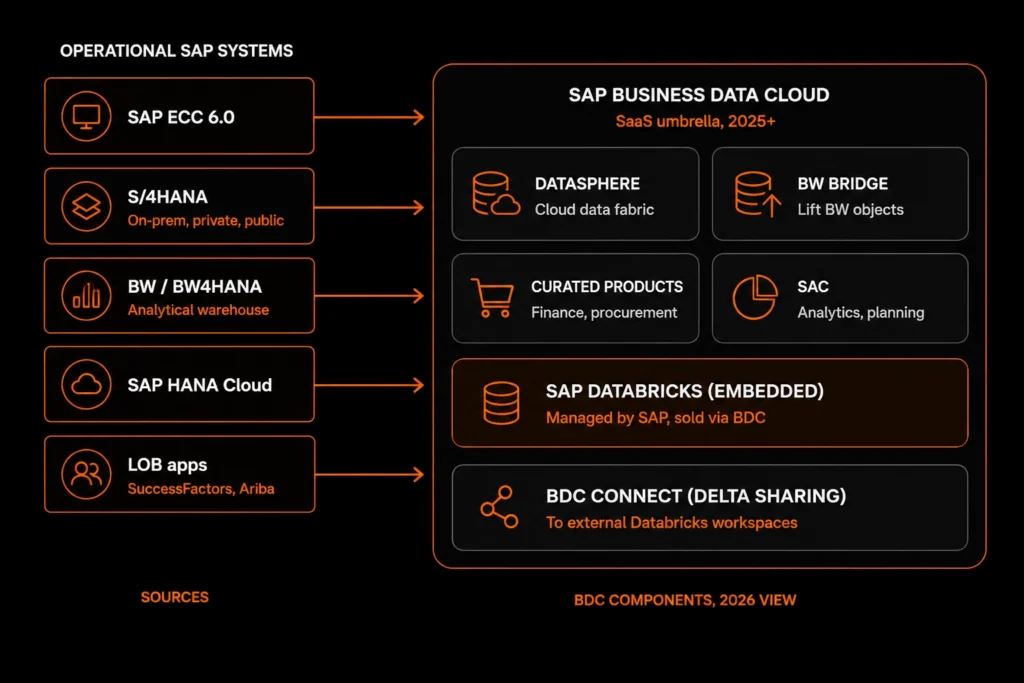
3.6 SAP Business Data Cloud (BDC), the 2025/2026 umbrella
Announced February 2025. BDC is the SaaS that now contains Datasphere, SAP Analytics Cloud, BW (as Bridge), curated SAP data products, Intelligent Applications, and the embedded SAP Databricks. SAP HANA Cloud became a native BDC component in the Sapphire 2026 cycle. For any architecture conversation starting in 2026, BDC is the term to plan around.
3.7 Line-of-business and edge SAP applications
Easy to forget but very common in scope: SAP SuccessFactors (HR, separate cloud), SAP Ariba (procurement), SAP Concur (T&E), SAP IBP (integrated business planning), SAP CRM / C/4HANA (customer experience suite), SAP Fieldglass. Each has its own APIs. BDC's curated data products are progressively expanding to cover these.
Practical takeaway: ECC-on-Oracle, S/4HANA Cloud public edition, BW/4HANA, and SuccessFactors look identical on an architecture slide. They are not. Map every system in scope to this list before scoping ingestion.
4. The target: what does the Lakehouse look like?
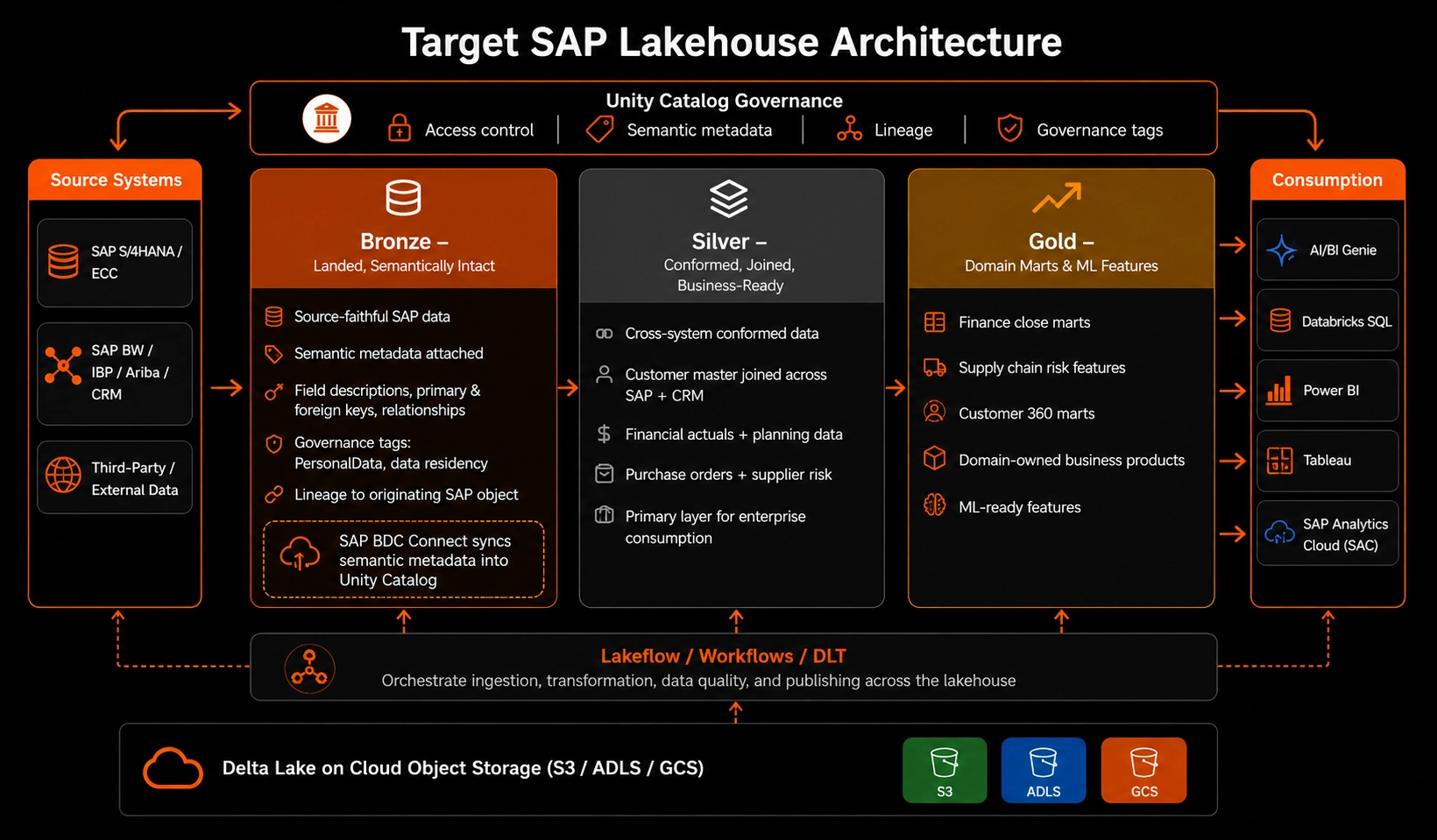
A defensible Lakehouse from SAP sources follows the medallion pattern, but with SAP-specific considerations at each layer.
Bronze, landed, semantically intact
Bronze stores SAP data as close to source as practical, preserving business context. This is not raw KUNNR columns with no documentation. It's source-faithful data with three things attached: the semantic metadata (field descriptions, primary keys, relationships), the governance tags (PersonalData classifications, data residency markers), and the lineage back to the originating SAP object. SAP BDC Connect's automatic semantic metadata sync into Unity Catalog has made this layer dramatically cleaner than it was even a year ago, table and column comments, primary and foreign keys, and PersonalData governance tags flow through automatically.
Silver, conformed, joined, business-ready
Silver is where SAP data becomes useful across the enterprise. Customer master joined across SAP and CRM. Financial actuals from S/4HANA joined with planning data from IBP. Purchase orders joined with supplier risk data from a third-party feed. This is the layer most consumers should actually be querying. It's also where the SAP-vs-everything-else boundary dissolves.
Gold, domain marts and ML features
Gold is purpose-built: finance close marts, supply chain risk features, customer 360 marts. Owned by domains, not by central IT. This is where democratization shows up as actual business outcomes.
What sits across all three layers
- Unity Catalog governs the entire Lakehouse, with SAP semantic metadata flowing in Bronze and carrying through.
- Delta Lake as the storage format, on the cloud's object store (S3 / ADLS / GCS).
- Lakeflow / Workflows / DLT orchestrate the pipelines.
- AI/BI Genie, Databricks SQL, and external BI tools (Power BI, Tableau, SAC) consume Gold.
5. How SAP data reaches the Lakehouse (Ingestion strategies)
There are seven materially different paths for SAP data integration. They differ on five axes that matter in a review: compliance with SAP's ODP support note, latency, business semantics preserved, total cost, and operational burden.
5.1 SAP BDC Connect for Databricks (Delta Sharing) ,the new strategic path
What it is: SAP publishes curated data products from BDC. A bi-directional, zero-copy Delta Sharing connector mounts them in your external Databricks Unity Catalog workspace. Generally available on AWS, Azure, and GCP. Secured with mTLS + OAuth (OIDC). Semantic metadata (display names, descriptions, primary/foreign keys, PersonalData governance tags) syncs automatically into Unity Catalog.
Why it matters for democratization: this is the cleanest path for getting trusted, governed, semantically rich SAP data into the hands of the wider data community without replication. A concrete example: BDC's finance data products natively present the simplified S/4HANA universal journal format (ACDOCA), which means data teams in Databricks don't have to manually reconstruct finance facts by joining legacy ECC tables (BSEG, BKPF, BSIK, etc.) on the Lakehouse side. The business model is preserved at the source.
Constraints worth scrutinizing:
- Requires BDC subscription. You buy BDC Capacity Units (CUs) from SAP; BDC Connect for Databricks consumes from that pool.
- Curated, not raw. You consume SAP-published data products (Financial Actuals, Purchase Orders, etc.), not arbitrary ECC tables. You can extend and join in Databricks; you cannot restructure the products themselves.
- Not for bulk replication. SAP positions BDC Connect for sharing. For bulk replication, SAP points customers at Premium Outbound Integration (POI) inside Datasphere.
- Cross-cloud egress is a real and often-missed cost. Delta Sharing itself doesn't charge, but the hyperscalers do. A common scenario: BDC is hosted on SAP's tenant on AWS, while the enterprise's primary Databricks Lakehouse runs on Azure. Every time Delta Sharing reads pull data across that boundary, AWS egress charges apply. The same applies for any cross-cloud or cross-region combination. Architects must model this explicitly in TCO, it's the single most underestimated line item in BDC Connect deployments.
5.2 SAP Databricks (embedded inside BDC)
What it is: a SAP-managed Databricks workspace that lives inside BDC. Sold by SAP. Governed by Unity Catalog. Pre-wired to the curated data products.
Strengths: shortest path from SAP data to Databricks SQL, ML, and AI. No connector to configure. Single contract.
Constraints to handle carefully, this is the area most likely to be questioned in review:
- Reduced feature set vs. native Databricks. SAP Databricks is positioned as an optimized pro-code environment for data science, ML/MLOps, exploratory notebook analysis, and Databricks SQL (BI). Production-grade data engineering features are deliberately excluded ,including Delta Live Tables, native Lakeflow Connect, advanced Workflows, and Streaming pipelines ,along with Databricks Marketplace (replaced by SAP's Datasphere Marketplace) and some AI/BI tooling (SAP prefers SAC for BI). Customers needing these capabilities must use a customer-managed, external Databricks workspace alongside SAP Databricks.
- SAP-managed release cadence. Updates roll out on SAP's schedule.
- Procurement constraint. SAP Databricks is only sold through BDC. Existing Databricks customers cannot bolt the curated SAP products onto their existing workspace, they must subscribe to BDC. Once they have BDC, they can choose to consume via SAP Databricks or via Delta Sharing into their existing external Databricks.
Most enterprises with an established Databricks footprint end up using SAP Databricks for SAP-specific work and keeping their existing workspace for cross-domain workloads, joined via Delta Sharing.
5.3 SAP Datasphere Replication Flow
What it is: a managed replication capability inside Datasphere/BDC that pushes data to a target, including cloud object stores (S3, ADLS, GCS), which Databricks then ingests via Auto Loader / Lakeflow.
Status: this is now SAP's recommended path for bulk replication following the ODP support-note restrictions. Uses extraction-enabled CDS views, supports delta where the source allows.
Constraints:
- Cost. Replication Flow consumes Datasphere capacity; large or highly concurrent flows can become expensive.
- Concurrency cap. A documented cap on concurrent replication threads, high-volume customers with many objects need a deliberate wave strategy.
- Cross-region egress for object-store landing zones in different clouds/regions.
5.4 Third-party ingestion tools (Fivetran, Qlik, Informatica, Precisely, BryteFlow, etc.)
What it is: validated ingestion partners with purpose-built SAP connectors that write directly to Delta Lake / Unity Catalog. Many integrate with Databricks Partner Connect.
Status post-ODP-restriction: SAP Note 3255746 restricted third-party use of the ODP RFC API. Tools that previously depended on ODP RFC had to adapt. Vendors including Microsoft (Azure SAP CDC connector), Fivetran, and Qlik have built compliant alternatives, typically using ODP OData (compliant but slower than the RFC path) or non-ODP interfaces. Some vendors (e.g., BryteFlow) emphasize SAP-certified extraction methods (ODP + OData) over RFC-based approaches.
Strengths: mature tooling, parallelized full + delta loads, dashboard monitoring, broad source coverage including pool/cluster tables and BW objects.
Constraints: subscription cost on top of Databricks cost; ODP-OData performance trade-off; vendor compliance must be re-verified for each tool against the current support note.
5.5 Direct JDBC to SAP HANA (Spark JDBC, ngdbc.jar)
What it is: Databricks notebooks read directly from HANA via the SAP HANA JDBC driver, pulling tables and calculation views into Spark.
Strengths: fast to prototype, supports filter and column pushdown.
Constraints worth weighing hard:
- Source-system load. Reads hit production HANA. Point at a read replica or HANA sidecar for anything non-trivial.
- No built-in CDC. Build your own watermark logic.
- Raw DB tables. No BAPI/RFC business logic applied, you lose what CDS views offer.
- Licensing. Direct HANA access typically requires HANA Enterprise Edition. Confirm with SAP licensing before scoping.
Good for: bulk initial loads, small-table reads, prototypes. Bad for: ongoing CDC or production replication.
5.6 Hyperscaler-native integration services
Each cloud has SAP-aware tooling that lands data in object storage for Databricks to pick up:
- AWS, Amazon AppFlow has a SAP OData connector landing in S3.
- Azure, Azure Data Factory / Synapse Pipelines has both a SAP HANA connector and a dedicated SAP CDC connector built on the ODP framework. The Azure SAP CDC connector is one of the more mature ODP-CDC implementations outside SAP itself.
- GCP, Cloud Data Fusion ships with SAP connectors (S/4HANA, BW, SLT, table reader). BigQuery Connector for SAP uses SLT for replication into BigQuery, from where Databricks on GCP can federate.
Most attractive when an organization is already heavily invested in the hyperscaler's data tooling.
5.7 SLT and SAP Data Services
SAP's own real-time and batch replication tools. SLT (SAP LT Replication Server) is well-known for trigger-based CDC; SAP Data Services (BODS) is the classic batch ETL platform. Still valid where already operationally embedded, particularly in BW Bridge scenarios. Increasingly displaced by Replication Flow + BDC Connect for new builds.
5.8 Side-by-side comparison
| Method | Real-time / Delta | Preserves SAP business semantics | ODP-Note compliant | Best for | Watch out for |
|---|---|---|---|---|---|
| BDC Connect (Delta Sharing) | Live, zero-copy | Yes, full semantic metadata sync | N/A (SAP-governed) | Strategic, governed sharing of curated data products | Requires BDC; curated only; cross-cloud egress |
| SAP Databricks (embedded) | Live | Yes | N/A | SAP-heavy DS/ML/SQL workloads, all-in-one | No DLT / Lakeflow / Workflows / Streaming, pair with external workspace |
| Datasphere Replication Flow | Minutes to hours (snapshot/restore) | Yes (CDS) | Yes (SAP-native) | Bulk replication to object storage | Concurrency cap; CU cost |
| Fivetran / Qlik / Informatica / BryteFlow | CDC available | Partial | Yes via ODP-OData / non-RFC | Mature, monitored ingestion at scale | Tool license cost; verify compliance |
| Spark JDBC to HANA | No CDC built-in | No (raw tables) | N/A (DB-level) | Bulk loads, prototypes, HANA sidecar | Source load; HANA license; no business logic |
| Hyperscaler native (AppFlow / ADF SAP CDC / Data Fusion) | Varies; ADF SAP CDC is true CDC | Partial | Yes (compliant paths) | Already standardized on that cloud | Coverage varies by SAP source |
| SLT / SAP Data Services | Real-time (SLT) | Yes (DB layer) | N/A (SAP-native) | Existing SAP shops, BW Bridge feeds | Aging stack; skills dependency |
6. Reference architectures for the SAP Lakehouse
6.1 Greenfield: S/4HANA → BDC → external Databricks Lakehouse
The cleanest 2026 architecture. SAP curates' data products in BDC. BDC Connect for Databricks shares them via Delta Sharing into the customer's Databricks workspace as a Unity Catalog catalog. Non-SAP data (clickstream, IoT, third-party feeds, CRM) lands in Databricks the usual way, Auto Loader, Lakeflow Connect, Fivetran. Bronze keeps SAP semantically intact; Silver joins across domains; Gold serves business marts. Unity Catalog governs end-to-end. ML and AI workloads consume both seamlessly.
6.2 Brownfield: large ECC estate + existing Databricks
ECC 6.0 still runs core operations. The pragmatic path:
- Use BW Bridge (or Datasphere directly where extractors permit) to absorb ECC extractor delta quirks.
- Use Replication Flow to land bronze data in S3 / ADLS / GCS.
- Auto Loader pulls into Bronze → Silver → Gold in Databricks.
- As S/4HANA rollout progresses, replace each ECC source with the CDS-based extraction-ready equivalent and, ideally, migrate to BDC Connect once the relevant data product is available.
This is also the architecture that buys the most time for skills transition, BW developers can keep contributing to the BW Bridge side while the Databricks team builds out the cross-domain layers.
6.3 Hybrid analytical: BW/4HANA as system of analytical record
Where BW/4HANA holds harmonized, business-trusted data, leave it in place. Use Datasphere to federate or replicate selected InfoProviders / aDSOs to the Lakehouse. Use Databricks to combine those harmonized metrics with non-SAP signals, clickstream, weather, social, IoT, for ML use cases BW was never designed to support.
7. Cloud-by-cloud: AWS vs Azure vs GCP for a SAP Lakehouse
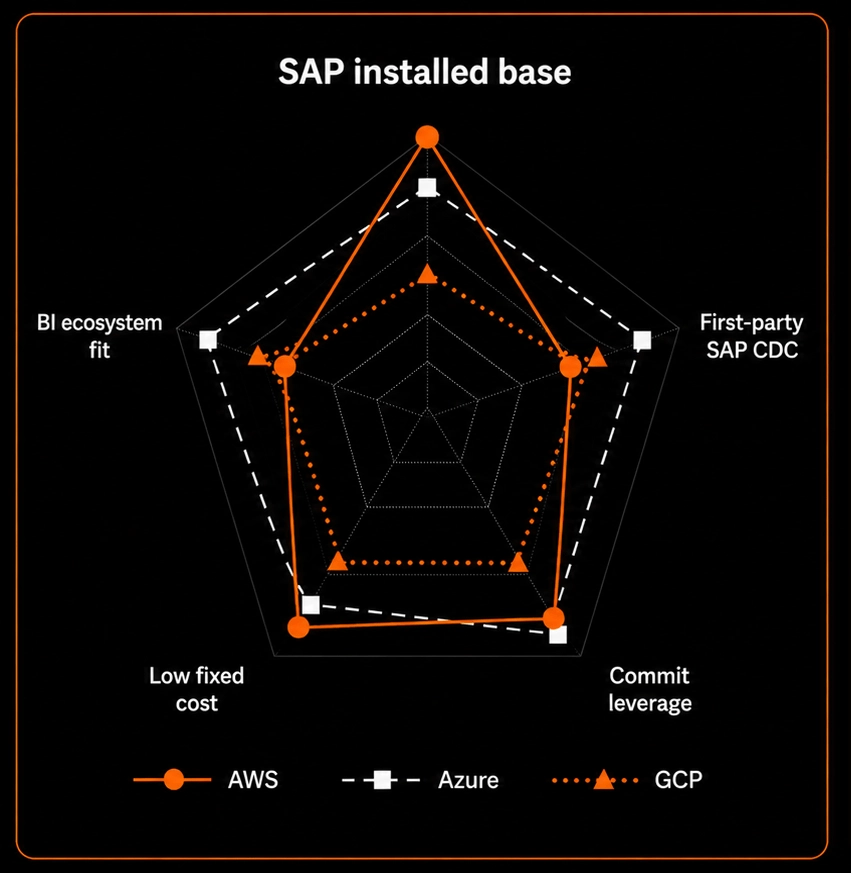
Databricks compute, Spark runtime, Delta Lake, Unity Catalog, and the notebook experience are functionally identical across the three clouds. SAP Databricks (the embedded variant) is offered on all three. What differs is the integration layer: identity, storage, networking, billing, native services, and SAP-specific connectors.
7.1 AWS
Strengths:
- Largest installed base of SAP on hyperscaler (long-running RISE with SAP on AWS commitments).
- Amazon AppFlow with SAP OData connector for SaaS-style ingestion to S3.
- AWS Marketplace consumption of Databricks counts against existing AWS commit, matters for organizations with EDP commitments.
- AWS PrivateLink for private connectivity between Databricks and SAP workloads.
Watchouts:
- Less first-party ETL coverage of SAP than Azure's SAP CDC connector; most teams end up combining AppFlow with Fivetran or another partner tool.
7.2 Azure
Strengths:
- First-party Databricks service ,provisioned through the Azure portal, on the Azure bill, integrated with Entra ID for SSO and RBAC.
- ADF / Synapse Pipelines has the most mature SAP CDC connector outside SAP itself, built on the ODP framework. A real differentiator for ECC and on-prem S/4HANA sources.
- Tight Power BI integration for downstream consumption.
- Strong fit for organizations on Microsoft Enterprise Agreements.
Watchouts:
- Standard tier retirement. New Standard workspaces stopped being supported April 1, 2026; existing Standard workspaces auto-migrate to Premium by October 1, 2026, with a meaningful DBU rate increase. Anyone scoping 2026/2027 needs Premium pricing baked in.
- Microsoft Fabric overlaps with Databricks for some workloads ,expect internal architecture debates.
7.3 GCP
Strengths:
- BigQuery federation from Databricks, useful when analytical workloads already live in BigQuery.
- Cloud Data Fusion ships with SAP connectors (S/4HANA, BW, SLT, table reader); strong low-code option.
- BigQuery Connector for SAP (SLT-based) where BigQuery is already standard.
- GKE-based deployment offers faster cold-start scaling for high-concurrency workloads in some scenarios.
Watchouts:
- Per-workspace GKE baseline cost of roughly $150–$200/workspace/month, driven by GKE cluster management fees plus minimum controller node compute. Even idle workspaces carry this fixed cost ,significant for organizations running many environments.
- Smallest installed base of the three for SAP workloads ,fewer SAP–GCP-specific partners and reference architectures.
7.4 Cost dimensions that apply everywhere
DBU rates vary by cloud, region, tier (Standard / Premium / Enterprise), and compute type (All-Purpose / Jobs / SQL / Serverless). Pre-purchased Databricks Commit Units (DBCUs) can save up to roughly 37% on 1–3 year terms. Regardless of cloud, egress between BDC's tenant and a customer-managed Databricks workspace in a different cloud or region is the most missed line item in TCO models.
8. A decision framework
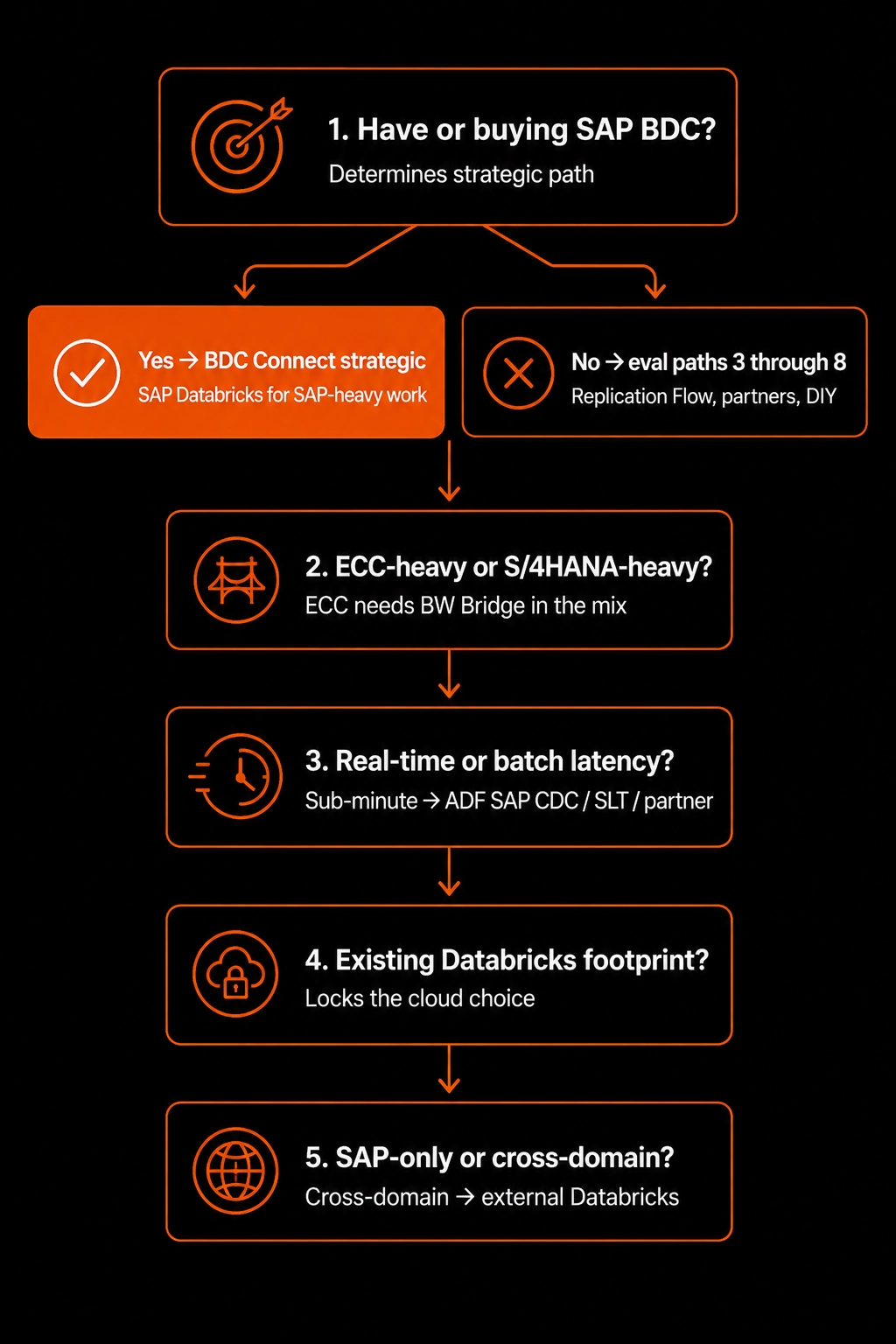
Five questions, in order. Each prunes the option space.
1. Do you already have, or will you buy, SAP BDC?
- Yes → BDC Connect into your Databricks workspace is the strategic answer for curated data products. SAP Databricks itself is a candidate for SAP-heavy net-new workloads.
- No → you're working from §5.3–§5.7.
2. Are your SAP sources predominantly ECC or S/4HANA?
- ECC-heavy → BW Bridge in the mix, more reliance on third-party tooling, more complex CDC.
- S/4HANA-heavy → CDS-based extraction-ready views + Replication Flow + BDC Connect is the cleanest path.
3. What is your latency requirement?
- Real-time / sub-minute CDC → Azure SAP CDC, Qlik, Fivetran, or SLT. Spark JDBC won't get you there.
- Hourly / daily → Replication Flow → object storage → Auto Loader is the workhorse.
4. Where does your existing Databricks footprint live?
- Azure → strong gravitational pull to stay on Azure for SAP work too.
- AWS → AppFlow + Fivetran is the common stack.
- GCP → Data Fusion + BigQuery federation worth evaluating.
- None → cloud choice is essentially a SAP-hosting decision (where does your RISE landscape live?).
5. Is the workload SAP-only or SAP + everything else?
- SAP-only analytics → SAP Databricks inside BDC is a viable single-vendor answer.
- SAP + non-SAP joined for ML / AI / cross-domain analytics → external Databricks with BDC Connect or third-party ingestion. Don't trap enterprise data inside the SAP perimeter ,that defeats the democratization goal.
9. Making it democratic: the work that doesn't show up in architecture diagrams
The architecture above is a necessary condition for democratization, not a sufficient one. Three pieces of work matter as much as the pipelines:
- Business glossary and data product ownership. Bronze tables with SAP semantic metadata are a starting point, not the finish line. Each domain, finance, supply chain, HR, needs to own its data products in the Lakehouse with named stewards, documented definitions, and SLAs. SAP BDC's curated data products give you a head start on the finance and procurement side; you're on your own for cross-domain marts.
- Access patterns that respect the principle of least privilege without blocking people. Unity Catalog row,and column-level security, attribute-based access control, and SAP BDC's PersonalData governance tags need to be configured deliberately. The default of "open by domain, restricted by sensitivity tag" is usually a better starting posture than "closed by default."
- Skills bridges, not skills replacement. BW developers, ABAP developers, and HANA modelers have deep knowledge of SAP business semantics that no Databricks training can replicate. The successful Lakehouse programs pair them with Spark / SQL / Python engineers rather than replacing them. Conversely, business analysts who lived in BEx queries need help moving to Databricks SQL and BI tools. Budget for this explicitly, it's where most "we built it, but nobody uses it" failures actually originate.
10. Open questions and risks worth calling out
Honest accounting of what's still moving:
- BDC Connect roadmap to other platforms. SAP has stated that BDC Connect for Amazon Athena, Snowflake, Google BigQuery, and Microsoft Fabric are on the roadmap, with general availability targeted for H2 2026. Relevant if you're advising on multi-target architectures.
- The Reltio acquisition brings multi-domain master data management directly into BDC, which will reshape master data governance conversations.
- ODP RFC restriction enforcement. The support note is published and broadly understood; the practical compliance state of every third-party connector continues to evolve. Re-verify each vendor before signing.
- Pricing. DBU rates, BDC Capacity Units, and Azure Standard-tier retirement have all changed within the last 12 months. Treat all TCO numbers as illustrative only.
- Curated data product coverage. BDC ships curated products for finance, procurement, and core supply chain today, with broader LOB coverage rolling out. Verify the specific products required for your use cases are GA at the time of scoping. on enforcement. The support note is published and broadly understood; the practical compliance state of every third-party connector continues to evolve. Re-verify each vendor before signing.
Here's a closing section drafted in the same voice as the rest of the blog. It ties together the three-domain expertise point, makes the case for thoughtful architecture over template solutions, and ends with a clean call to action for Syren without sounding salesy.
11. Closing thought: the architecture is only as good as the people designing it
Everything in this article points to a single, uncomfortable truth: there is no template for SAP Lakehouse. The right architecture for a discrete manufacturer running ECC on Oracle with a BW/4HANA reporting layer looks nothing like the right architecture for a process manufacturer mid-flight on a RISE with SAP migration with SuccessFactors and Ariba already in BDC. Both can be defended in review. Both can fail in production if the design doesn't account for what the business actually does day to day.
Getting this right requires fluency in three domains that rarely sit in the same head, or even the same team:
- SAP. Not "we've heard of SAP," but a working understanding of CDS views vs. classic extractors, what BW Bridge actually does, why ACDOCA changed everything for finance analytics, and where BDC's curated data products end and your own modeling begins. Without this, the Lakehouse becomes a faster way to query badly understood data.
- Databricks and the Lakehouse. Unity Catalog governance patterns, when to use Delta Live Tables vs. Workflows, how to design medallion layers so Silver actually gets consumed, how to keep DBU spend from compounding quietly. Without this, the Lakehouse becomes an expensive data lake.
- The business itself. Manufacturing process knowledge, supply chain operating models, finance close mechanics, the difference between what a plant manager asks for and what they actually need. Without this, the Lakehouse becomes a technically impressive system that nobody uses.
The architectures that scale, that stay within budget, and that actually get used in production are the ones designed by people who can hold all three perspectives at once. That's rare. Most SAP integrators are deep on the first domain and thin on the other two. Most Databricks practitioners are deep on the second and thin on the first and third. The combination is what turns "we moved SAP data to Databricks" into "our supply chain team is using SAP-grounded ML in their weekly S&OP cycle."
This is the work Syren does. We sit at the intersection of manufacturing and supply chain process knowledge, deep SAP experience, and production Databricks delivery, and we use that combination to design Lakehouse architectures that are scalable, cost-defensible, and actually adopted by the business teams they're built for.
If you're an enterprise leader looking to unlock real value from your SAP data, whether you're scoping a greenfield BDC + Databricks build, navigating a brownfield ECC estate, or trying to make sense of which of the seven ingestion paths fits your landscape, the Syren team would be glad to talk. Reach out to us, and let's design something worth defending in your next architecture review.


