Summary
- Databricks CEO Ali Ghodsi recently noted that "over 80% of the databases that are being launched on Databricks are not being launched by humans, but by AI agents." If that's where enterprise data is heading, the harder question is how to do it safely. We built AI Pricing Agent to find out.
- Pricing Agent is a working application where a pricing manager describes a price change in natural language, an AI agent generates and previews the SQL on a Lakebase sandbox, a Model Serving endpoint predicts demand impact per SKU, and a human approves or discards before anything reaches production.
- The application runs entirely on Databricks: Lakebase for the operational database, Foundation Models for SQL generation, Model Serving for demand prediction, and Databricks Apps for hosting.
- The point is not pricing software. It's the architectural pattern: how do you let AI write to operational data without breaking production? This post documents what worked, what surprised us, and where Lakebase did real work that other databases can't.
What we wanted to find out
When Databricks shipped Lakebase, the early conversation focused on its OLTP capabilities managed Postgres, autoscaling, scale-to-zero. We covered that ground in our previous post. But the more interesting question was further out: what does Databricks Lakebase enable that traditional Postgres doesn't?
The signal was hard to miss. Databricks CEO Ali Ghodsi recently noted that "over 80% of the databases that are being launched on Databricks are not being launched by humans, but by AI agents." If agents are creating databases at that scale, the harder problem is letting them safely act on the data inside.
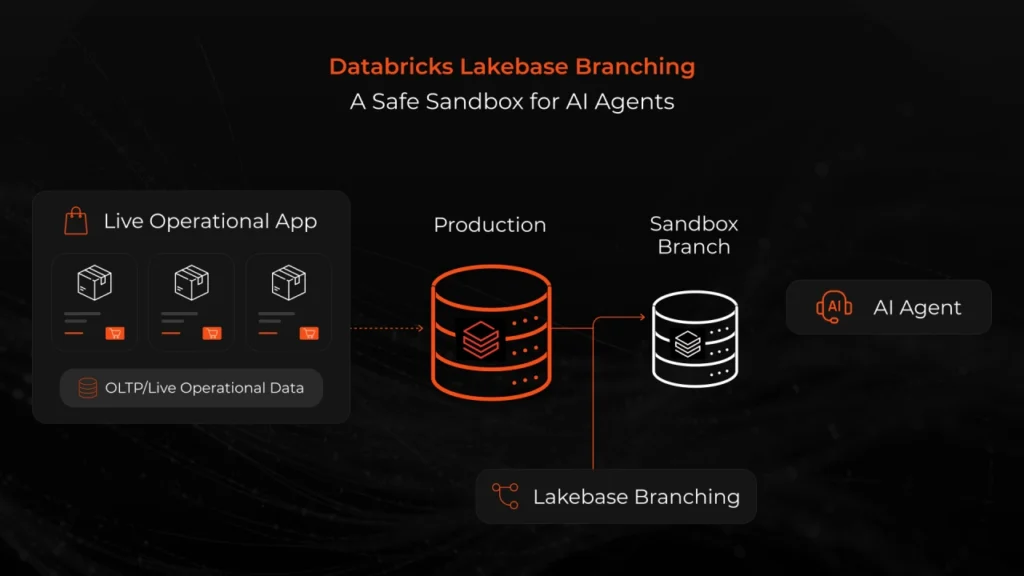
The answer, after working with the platform, was clear: copy-on-write database branching. And the use case where branching genuinely matters isn't backups or testing; it's letting AI agents act on live operational data safely.
That hypothesis became brief for this evaluation. Build an application where an AI agent makes destructive changes to a real e-commerce database, but with infrastructure that prevents anything bad from ever reaching production. Measure what's possible today.
We chose pricing operations as the test case for three reasons. Pricing changes are recognizably risky with a wrong discount costs real margin. The decision pattern (analyst proposes, system simulates; manager approves) is industry-standard going back decades. And it touches every Lakebase capability we wanted to evaluate: OLTP for the storefront, branching for the sandbox, Model Serving for impact prediction, and audit logging for governance.
The application: Pricing Agent
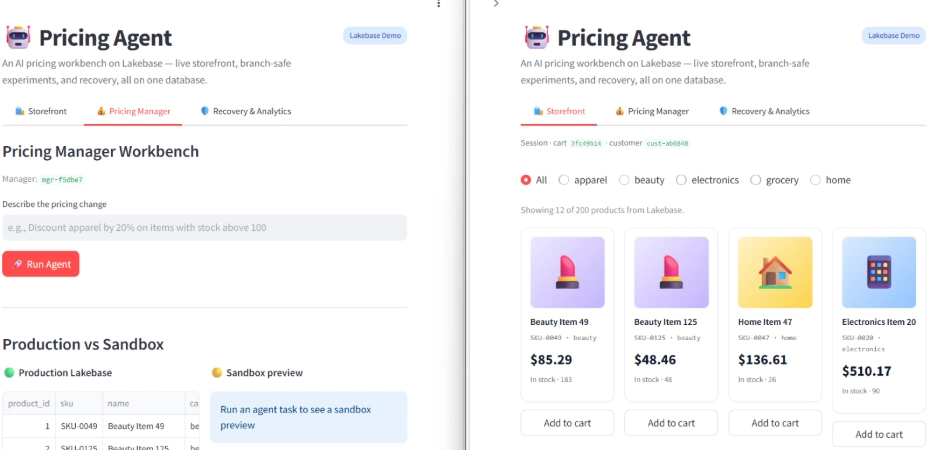
Pricing Agent has two surfaces, both running on the same Lakebase database.
The storefront is a normal e-commerce front end. Customers browse products, add to cart, place orders. Every action is a real Postgres transaction with row-level locks. Latencies are visible in the UI on every action.
The pricing workbench is where the AI agent lives. A pricing manager types intent in natural language. The agent generates SQL, runs it on a sandbox preview, calls a demand model for every affected SKU, and waits for the manager to approve or discard.
When approved, the changes commit to the production branch in a single atomic transaction. The storefront, which has been serving customers the entire time, picks up the new prices on the next page to load. No deployment, no cache invalidation, no ETL.
Phase 1: Data model and OLTP foundation
The Lakebase schema has six tables, all in one Postgres-compatible database:
| Table | Purpose | Written By |
|---|---|---|
| products | Source of truth for the catalog | Customer (stock decrement) and manager (price changes) |
| cart_items | Transient cart state | Customer |
| orders | Order history | Customer |
| order_items | Order line items | Customer |
| pricing_experiments | Every AI experiment, committed or discarded | Manager (via app) |
| price_change_log | Per-SKU audit trail of price changes | Manager (on commit) |
These tables drive the entire application. There is no second database for analytics. There is no ETL pipeline. Audit reports, BI dashboards, and the storefront all read from the same Lakebase.
Every customer interaction is wrapped in a transaction. Adding to cart locks the product row, validates stock, and inserts a cart line:
Order placement is a multi-table commit that creates the order, decrements stock and clears the cart in one atomic step. If two customers try to grab the last unit at the same time, row-level locking sorts it out.
This isn't a novel. It's just Postgres. But it's the workload running while the agent experiments on the other side of the app, and it's the workload that has to keep running uninterrupted when the agent experiment commits.
Phase 2: The agent flow
A manager opens the pricing workbench and types:
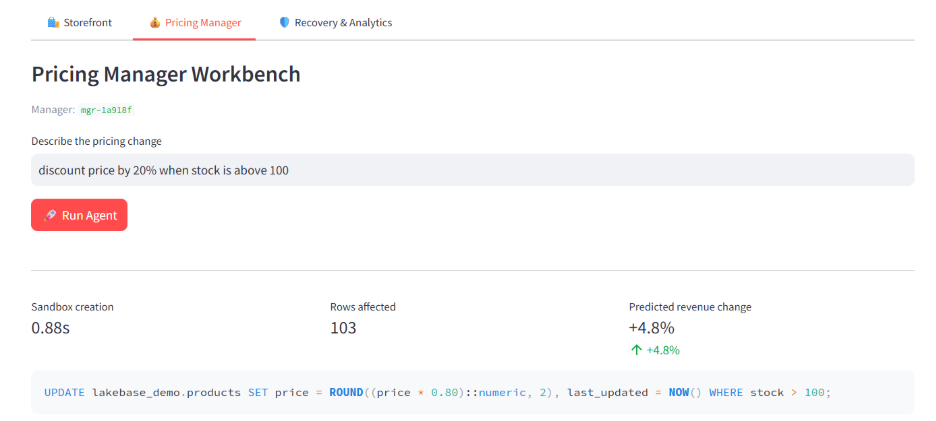
Discount price by 20% on items with stock above 100.
Behind the scenes, six things happen in sequence.
Step 1: Generate SQL: The app calls an LLM via the Databricks Foundation Models endpoint with the schema, the user prompt, and a system prompt that constrains output to a single PostgreSQL UPDATE or DELETE statement. The response comes back in 0.5–1.5 seconds.
Step 2: Create a Lakebase branch: The app calls the Lakebase branching API, which spins up a new Postgres environment in approximately 1.5 seconds using copy-on-write storage. The branch inherits the schema and data of the production branch but stores only what changes. Production stays completely untouched and continues serving the storefront.
Step 3: Run the SQL on the branch: The proposed change is applied to the branch's copy of products. Production prices stay where they are.
Step 4: Call the demand model: For each affected SKU, the app builds a feature payload (price, base price, stock, day of week, category) and calls the demand prediction Model Serving endpoint. The model returns predicted units sold per SKU.
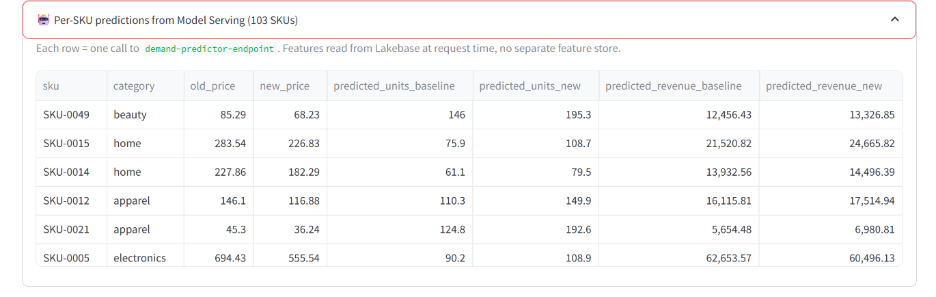
Step 5: Aggregate predictions: The app multiplies predicted units by proposed prices to get projected revenue per SKU. It aggregates a total revenue change percentage and a per-SKU breakdown.

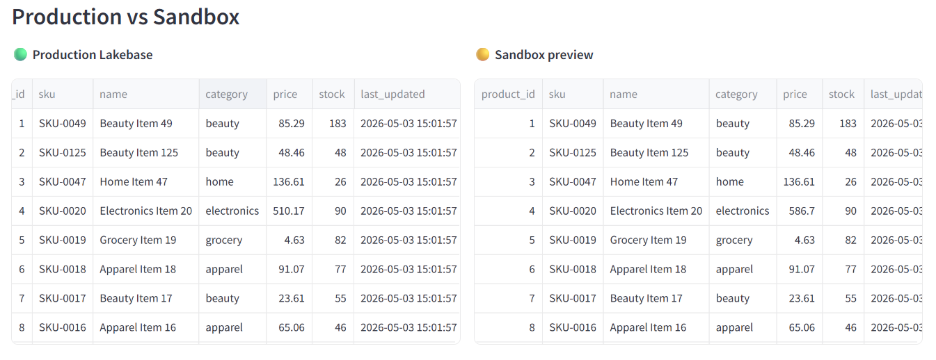
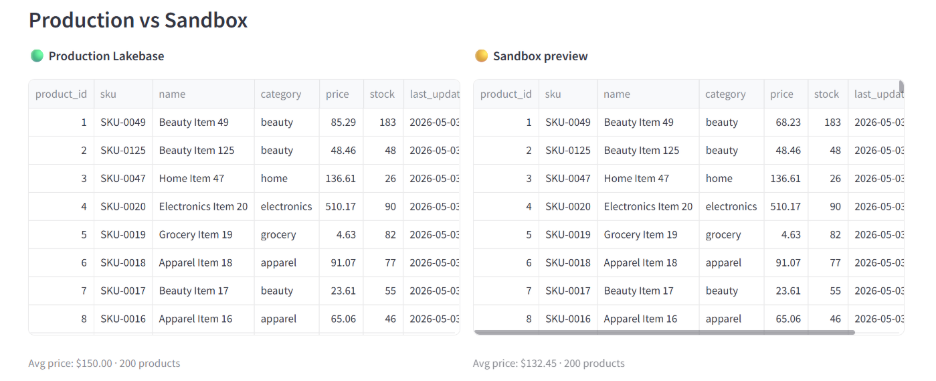
Step 6: Show the manager the diff. Side-by-side dataframes: production prices on the left, branch prices on the right. The manager reviews and decides.
Phase 3: Why a sandbox at all?
It's tempting to skip the sandbox branch. The model is good, the SQL looks right, just commit it.
The problem isn't whether the SQL is syntactically valid. It's whether the change does what the human meant. A 20% discount sounds reasonable until you find that it cuts margin on your highest-stock SKUs by half because they happen to be your lowest-margin ones. That's not a SQL problem. It's a business judgment problem, and the human need to see the consequence before it's real.
A sandbox branch makes that possible. The agent runs its SQL on a copy of production. The manager sees the diff. The model predicts the demand response. If anything looks off, discard the branch and the production database never knew it happened.
Think of it like a pull request for your database. The author proposes a change, CI runs the tests, a reviewer looks at the diff, and only then does the change merge. Lakebase branches are the database equivalent.
This is the unique thing Lakebase enables. Most pricing tools today use staging tables, shadow columns, or full snapshot environments to fake this, all of which are slower, more expensive, or both. Copy-on-write branching is the first database-native answer.
Phase 4: Approval and atomic commit
The manager clicks Approve. The app commits the selected changes in a single transaction:
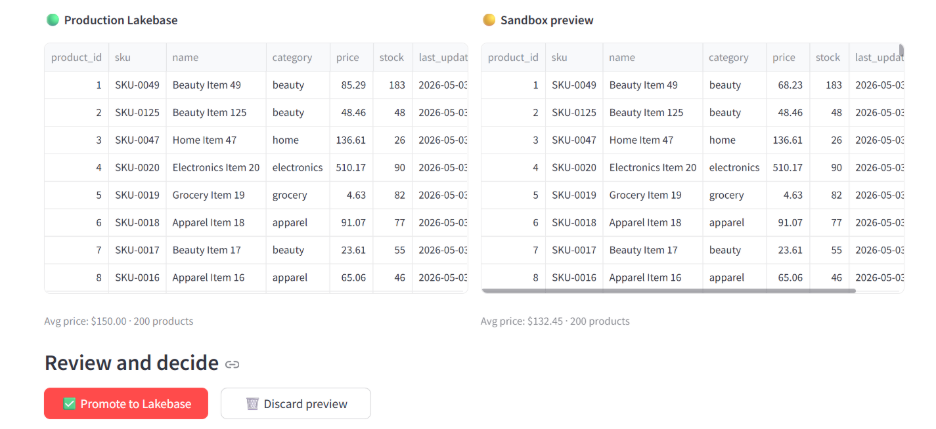
Once the transaction commits, the branch is deleted. Lakebase doesn't merge branches the way git does — promotion is "apply the changes I selected from the branch to production, then throw the branch away." Discard works the same way without the apply step: the branch is deleted, production never sees the changes.
The optimistic lock on last_updated matters more than it looks. With a single user, it's invisible. With two managers running experiments concurrently on overlapping SKUs, it's the difference between "this works" and "this corrupts data." If the first manager's commit changes a SKU's last_updated before the second manager's commit, the second commit's WHERE last_updated = $expected returns no rows and the entire transaction rolls back. The second manager has to refresh and try again.
After committing, the manager refreshes the storefront window. SKU-0049, a Beauty Item that was $85.29 a moment ago, now shows $68.23. A customer adding it to their cart sees $68.23 and pays $68.23.
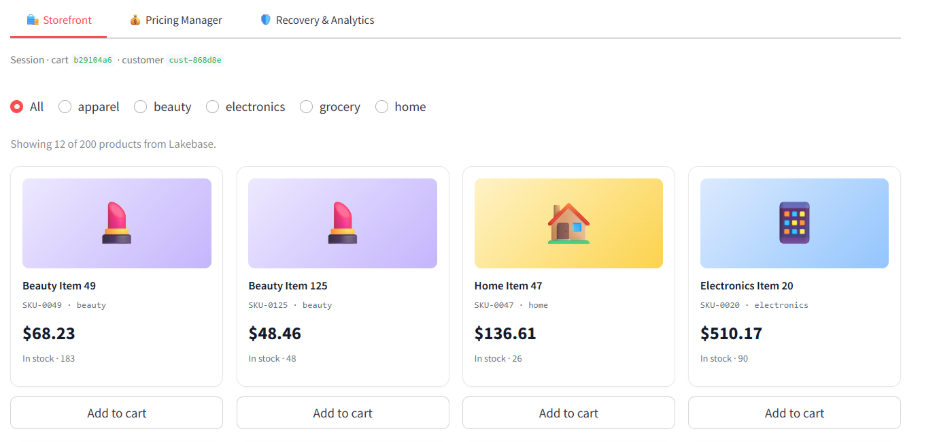
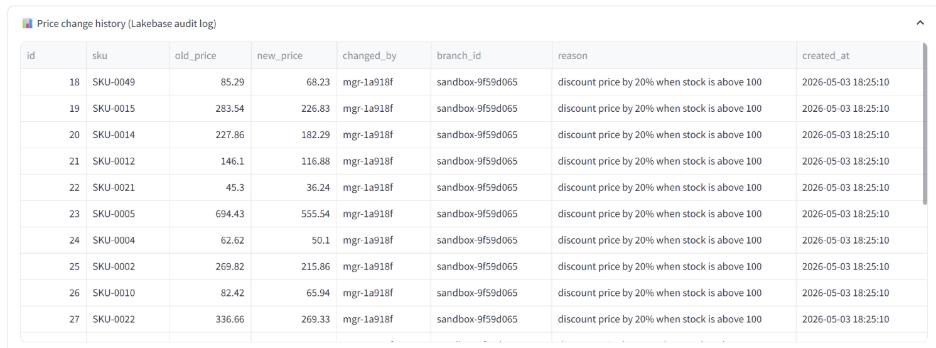
The audit trail comes for free. Because every price change writes to price_change_log and every experiment writes to pricing_experiments, both queryable from the same Lakebase database, there's nothing extra to set up for governance. Compliance can run SQL against the audit log. BI dashboards can join price changes against revenue.
Phase 5: When something goes wrong
Pricing changes go wrong sometimes. An agent misinterprets a prompt. A manager fat-fingers an approval. A bug in the SQL parser drops a WHERE clause. The recovery story matters more than the prevention story.
The Recovery & Analytics tab demonstrates two capabilities.
Point-in-time view. Reconstruct what the database looked like at any point in your retention window. In production, Lakebase point-in-time branches do this at the storage layer. In this demo we approximate the same answer by replaying the audit log. Either way, the manager can see exactly what changed and when.
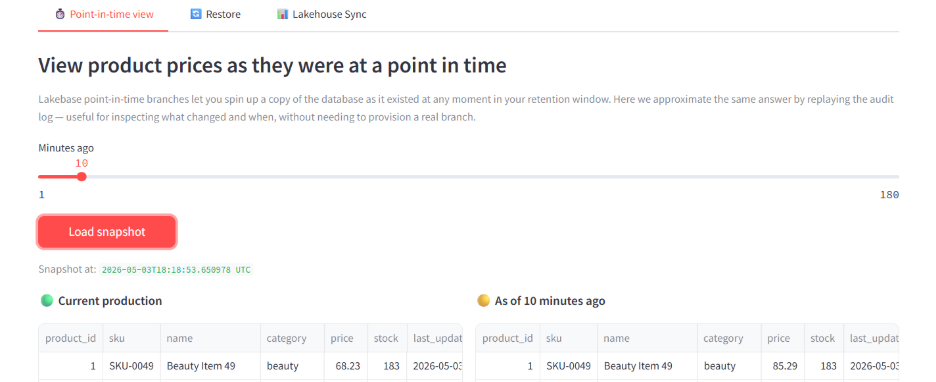
Instant restore. Roll back to a chosen timestamp atomically. To demonstrate the flow, the app includes a "Simulate bad commit" button that applies an obviously-wrong 80% discount to all apparel. The storefront immediately reflects broken pricing.
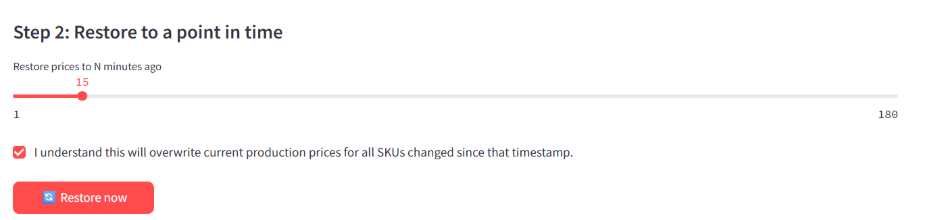
Trigger Restore from the same tab, slide the timestamp back five minutes, and confirm. The app rolls back every change made after that timestamp in a single transaction, with an audit entry for each rollback.
The whole rollback is atomic. Either every affected SKU restores or none of them does.
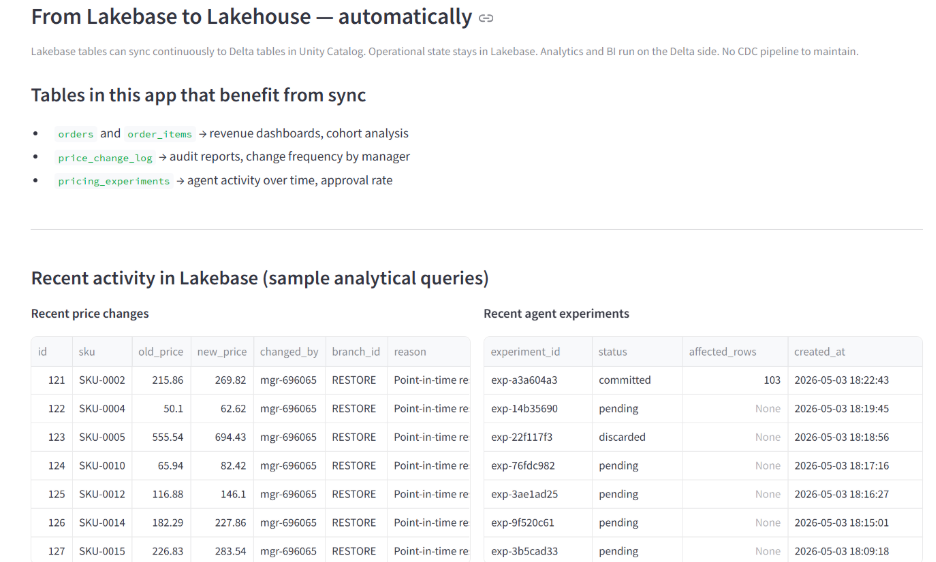
Phase 6: From operational state to lakehouse, automatically
The AI Pricing Agent isn't only an OLTP application. It's also a continuous source of analytical data: orders, price changes, experiment outcomes, agent activity. All of it queryable from Delta tables via Lakehouse Sync, with no CDC pipeline to build.
In a production deployment, an AI/BI dashboard would read from the synced Delta tables and answer questions like:
- Revenue impact of price changes by category, last 30 days
- Approval rate per pricing manager
- Average sandbox-to-commit time for experiments
- Distribution of agent prompt types over time
No data movement. Operational data flows into the lakehouse continuously, governed by Unity Catalog the same way the OLTP tables are.
What this pattern needs that traditional Postgres doesn't have
To put the architectural advantage in concrete terms:
| Capability | Traditional Postgres | Lakebase |
|---|---|---|
| Sandbox for AI experiments | Staging table, shadow column, or full snapshot environment | Copy-on-write branch in ~1.5 seconds |
| Sandbox storage cost | Full duplication of touched data, often whole DB | Only changed rows are stored separately |
| Sandbox creation time | Minutes to hours (snapshot/restore) | ~1.5 seconds |
| ML feature serving | Separate Redis or feature store, synced via pipeline | Read directly from same database, no sync |
| OLTP + analytics on same data | Two databases plus CDC pipeline | One database, Lakehouse Sync to Delta |
| Governance | Separate access control per system | Unity Catalog across operational and analytical |
| Recovery from bad agent commit | Restore from last backup; minutes-to-hours of lag | Instant restore to any retention-window timestamp |
For pricing software vendors building on traditional databases, every one of these capabilities is a custom build. For applications on Lakebase, they're platform features.
Lessons from the build
3.1 General Instructions: Be specific, not vague
Five things stood out building this.
1. The branching part was the easiest part. Once you have a Lakebase instance, creating a branch is one API call. The hardest engineering problems were nothing to do with Lakebase, they were parsing the LLM's output to figure out which rows would actually be affected, deciding what level of detail the manager needs in the diff view, and handling the case where the LLM generates SQL the parser doesn't understand.
2. Optimistic locking is more important than it looks. The conflict scenario is invisible with one user. With two managers running concurrent experiments, it's the difference between "this works" and "this silently corrupts data." Plan for concurrent users on day one. Adding it later is painful.
3. Scale-to-zero shapes the development economics. Each experiment is a sandbox that exists for minutes. Across a team of analysts running dozens of experiments per day, paying for idle compute would dominate the cost. Lakebase's autoscaling-with-zero-floor turns this from a budget conversation into a feasible workflow.
4. The model isn't the value driver, the integration is. Our gradient boosting demand model gets to about 0.73 R² on synthetic data. A real production pricing model would be more sophisticated. But the architectural value isn't model accuracy, it's that the model reads features from the same Lakebase tables the storefront reads from. No feature store. No offline/online skew. The current price the model uses is the same price customers see right now.
5. The audit log is the second-most-important table in the schema. Every price change writes to it. Every experiment writes to it. Every restore writes to it. When something goes wrong and the question becomes "what changed and who changed it," the answer is one SQL query against the same database.
Where this pattern goes beyond pricing
Pricing is one use case. The same shape, natural language prompt, AI-generated mutation, sandbox preview, model-scored impact, atomic commit with audit, fits other operational decisions.
Inventory rebalancing across warehouses. Customer credit limit adjustments. Bulk subscription tier changes. Reclassifying records for compliance remediation. Anywhere a human currently approves bulk database changes by reading a spreadsheet, this pattern can replace the spreadsheet.
The model and the validation logic change between use cases. The Lakebase plus branch plus commit pattern stays the same.
Conclusion
When we started this exercise, we wanted to know whether AI agents could safely write to live operational data on Databricks today, and what made it possible. The answer turned out to be more concrete than expected.
What makes this pattern feasible isn't any single Lakebase feature. It's the combination. Branching gives the agent a safe place to act. OLTP gives the storefront real transactional integrity. Model Serving on the same data closes the loop between prediction and operational state. Lakehouse Sync makes everything queryable for analytics without ETL. Unity Catalog governs the whole thing as one system.
These pieces have always existed separately. Putting them on one platform is what made this app a few hundred lines of code instead of a multi-quarter integration project.
For organizations building AI agents that need to act on operational data, Lakebase is the substrate that makes the architecture honest. The agent is sandboxed by default. The audit trail is automatic. The recovery story is real. The analytics layer comes for free.


