
Over the past two years, we’ve seen a wave of enterprises, from HLS giants to CPG leaders, accelerating their move to Databricks. And it’s not hard to understand why. As data volumes explode and AI becomes a board-level priority, teams are realizing that their legacy data stacks can’t keep up. Enterprises today want a platform that can unify data, analytics, and machine learning without the constant friction of moving data across tools or stitching together multiple engines. Databricks has become that platform.
Here’s the catch most teams don’t talk about: Migrating to the Lakehouse doesn’t automatically clean up years of inconsistent data, broken pipelines, or quality gaps. In fact, many enterprises only discover the extent of their data quality issues after they start migrating.
While some enterprises are still early in their journey, trying to standardize ingestion, set up lineage, or define quality rules across business units. Others are midway through, running workloads on Bronze but struggling to trust the Silver layer. Some are further ahead, building AI/ML pipelines, but noticing inconsistent model outputs because downstream data isn’t reliable.
Regardless of the stage, the pattern is the same:
Moving to Databricks spotlights long-standing data quality challenges, and enterprises need a scalable, automated, engineering-first approach to fix them.
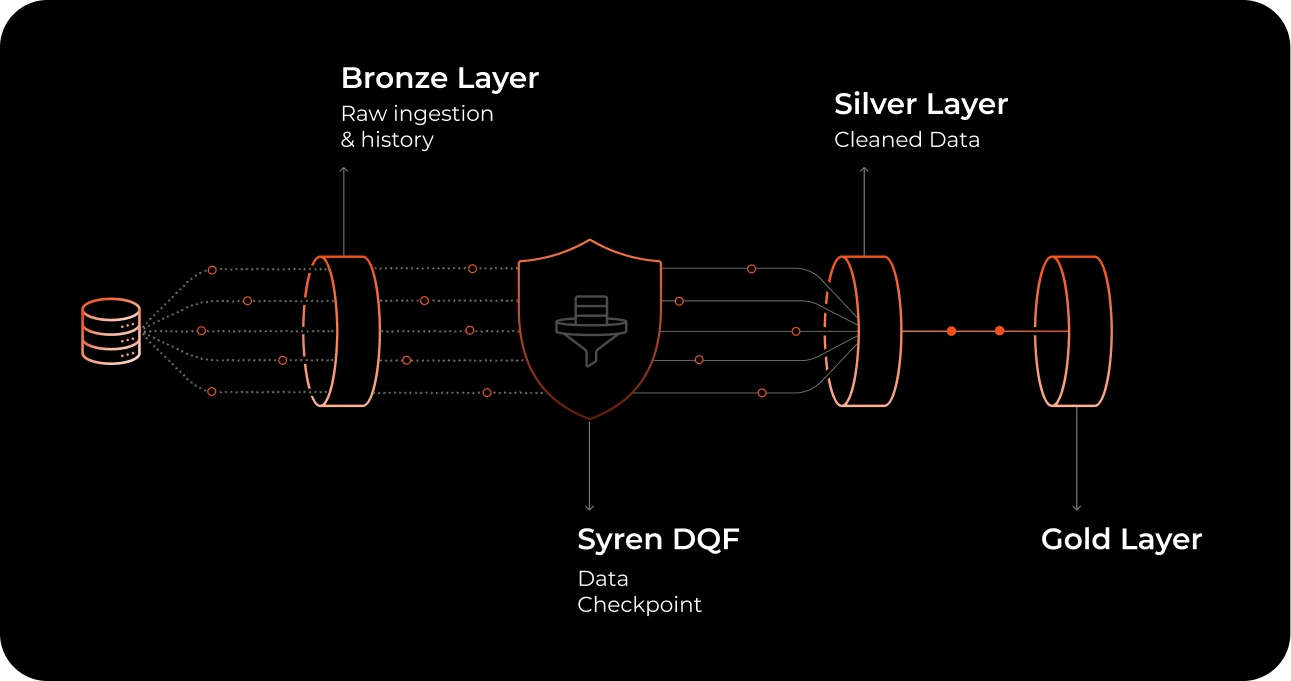
Syren’s AI-Augmented Data Quality Framework (DQF) is a reusable accelerator built natively for Databricks, designed to standardize data quality checks, incorporate anomaly detection, and provide automated remediation for ingestion and refined datasets.
The framework integrates with Delta Lake, Unity Catalog, Delta Live Tables, MLflow, and Databricks Workflows, ensuring that quality controls become an embedded part of every data pipeline rather than a set of ad-hoc scripts.
Problem Statement: What Existing Lakehouse Pipelines Lack
Enterprises migrating to Databricks struggle to ensure data accuracy, consistency, and trust across massive datasets. When modernizing their platforms, they often rely on legacy data quality tools that do not provide the scalability, lineage visibility, or Spark-native integration needed for Lakehouse pipelines.
This results in:
- Fragmented rule implementations
- Inconsistent data validations across ingestion layers
- Limited visibility into upstream issues
- Slower onboarding of new datasets
- Difficulty maintaining quality at scale
Syren addresses this gap with an AI-augmented, Databricks-native Data Quality Framework that integrates directly into Lakehouse pipelines.
Built for Databricks Lakehouse
DQF is built from the ground up for Databricks, leveraging native services to deliver speed, transparency, and governance at scale. Instead of treating data quality as a separate process, the framework embeds it directly into Databricks pipelines, as a reliability firewall.
Where AI Changes the Quality Equation
The framework builds on the best of Databricks’ native capabilities, Delta Live Tables, Unity Catalog, MLflow, and Databricks SQL, and layers in targeted AI components that eliminate repetitive engineering effort:
- Anomaly Detection Model: Learn from historical metadata to identify outliers beyond fixed rule logic.
- LLM-Based Rule Generator: Auto-suggest validation rules by interpreting schema profiles and column statistics.
- Auto-Imputation Engine: Recommends best-fit fill values for incomplete or missing data.
- Drift Detection & Trend Analytics: Tracks evolving data patterns and highlights schema or distribution shifts before they become production issues.
These components turn data quality into a learning, adaptive system, rather than a fixed rules engine.
| Databricks Component | Role in DQF |
|---|---|
| Delta Lake | Acts as the foundational storage layer, enabling ACID transactions and time travel for quality auditing. |
| Delta Live Tables (DLT) | Automates pipeline execution and enforces data quality expectations through declarative workflows. |
| Unity Catalog | Provides unified governance for rules, datasets, and metadata, ensuring lineage and access control. |
| Databricks Jobs & Workflows | Orchestrate end-to-end quality validation and remediation cycles. |
| MLflow & AI Integration | Enable anomaly detection and pattern-based issue prediction for proactive quality management. |
Syren’s DQF Architecture
A core strength of Syren’s AI-Augmented DQF lies in its layered design, which mirrors how data naturally flows through the Databricks Lakehouse. Each layer contributes a specific reliability function, and together they create a continuous, automated quality pipeline.
Data Ingestion
The framework connects directly with Databricks-native and external systems, pulling data from Volumes, Delta Tables, Kafka Streams, and third-party sources such as Fivetran. Ingestion can be orchestrated through Auto Loader or Delta Live Tables (DLT), ensuring that both batch and streaming datasets enter the pipeline consistently.
Profiling & Metadata Layer
Once data is ingested, the DQF generates detailed column-level statistics—minimums, maximums, null percentages, and unique counts. This baseline profiling is enhanced with AI models, including Isolation Forest, Prophet, and Autoencoders, which detect anomalies beyond traditional checks. LLM-based semantic tagging provides additional intelligence by understanding relationships and contextual meaning within the data.
Hybrid Rule Engine
The rule engine blends rule-based and AI-driven validation. Large language models (LLMs) generate and adapt rules dynamically, removing the need for manual configuration. Natural-language instructions such as “Ensure order_amount is never negative” can be interpreted directly, making rule authoring more intuitive and scalable.
DQ Analyzer
Validation happens through Databricks notebooks or DLT pipelines, where the framework executes rules, detects anomalies, and provides confidence scoring. AI-enhanced root-cause analysis summarizes why data failed validation and identifies patterns across batches or datasets.
Auto-Fixer
When issues are detected, the framework applies AI-driven corrections using contextual inference. For example, if a city field is missing, the system can infer it automatically from a postal code. These fixes ensure that quality improvements happen in real time, not just in audit reports.
Monitoring & Feedback Loop
Monitoring dashboards built on Databricks SQL provide real-time visibility into data quality trends. Genie Slack integration delivers alerts, explanations, and DQ summaries directly to engineering or business teams. The framework also learns from user overrides to reduce false positives and improve rule accuracy over time.
AI-Augmented Pipeline Flow
The full lifecycle follows a closed-loop flow:
Data Sources → Ingestion → Profiling → Hybrid Rule Engine → Analyzer → Auto-Fixer → Monitoring → Feedback Loop
This ensures that data is continuously validated, corrected, and improved with every cycle.
Intelligence Models Used
The DQF leverages a comprehensive library of anomaly detection, statistical testing, forecasting, and generative AI models—including Isolation Forest, Autoencoders, Prophet, GPT-based LLMs, KS-Test, Jensen–Shannon Divergence, and LangChain-enabled inference—while utilizing MLflow for model lifecycle management, deployment, and governance.
What Makes Syren’s Approach Different
Syren’s DQF is not a concept; it is a deployable accelerator. Its key differentiators are:
- Built natively for Databricks (Delta, UC, MLflow, DLT, Workflows)
- Strong handling of supply-chain and manufacturing data issues (timestamps, batch IDs, multi-source merges, missing operational metadata)
- AI-assisted rule inference
- ML-driven anomaly monitoring
- Reusable across industries
- Fully integrated observability layer
- Engineered to reduce manual QA effort significantly
This makes the framework suitable for any enterprise scaling production analytics and AI.
Conclusion
The AI-Augmented DQF ensures that data graduating into Silver is validated, anomaly-checked, remediated, scored, and auditable, all within a standardized Databricks-native architecture.
This directly improves:
- Pipeline reliability
- Model stability
- SLA adherence
- Regulatory compliance
- Data onboarding velocity
With this accelerator, Syren has turned data quality from a manual, table-by-table effort into a scalable, automated, intelligence-driven layer on the Lakehouse.


