
Building, integrating, and operating a compliance engine that fits inside your existing content and regulatory stack.
The bottleneck has moved
Content creation isn't the slow part in pharma anymore. Compliance review is.
Global pharma spends about $30 billion a year on content. U.S. output rose nearly 30 percent in a single recent year. GenAI on the creation side has only made the front of the funnel faster. So where does the time go now? Downstream, in compliance.
Medical, legal, and regulatory (MLR) review averages around 21 days globally. Pre-review steps add anywhere from 5 to 150 days per asset. Layer on medical affairs review, pharmacovigilance triggers, and regulatory submission prep, and the gap between "we made it" and "we can use it" is where the time and money disappear.
Most of these companies already have content creation and dissemination teams that work fine. What they don't have is a dedicated compliance engine: an agentic AI compliance system that lives inside the validation step of the content lifecycle, plugs into whatever regulated content management platform they already run, and turns compliance from a serial human bottleneck into a parallel, augmented one.
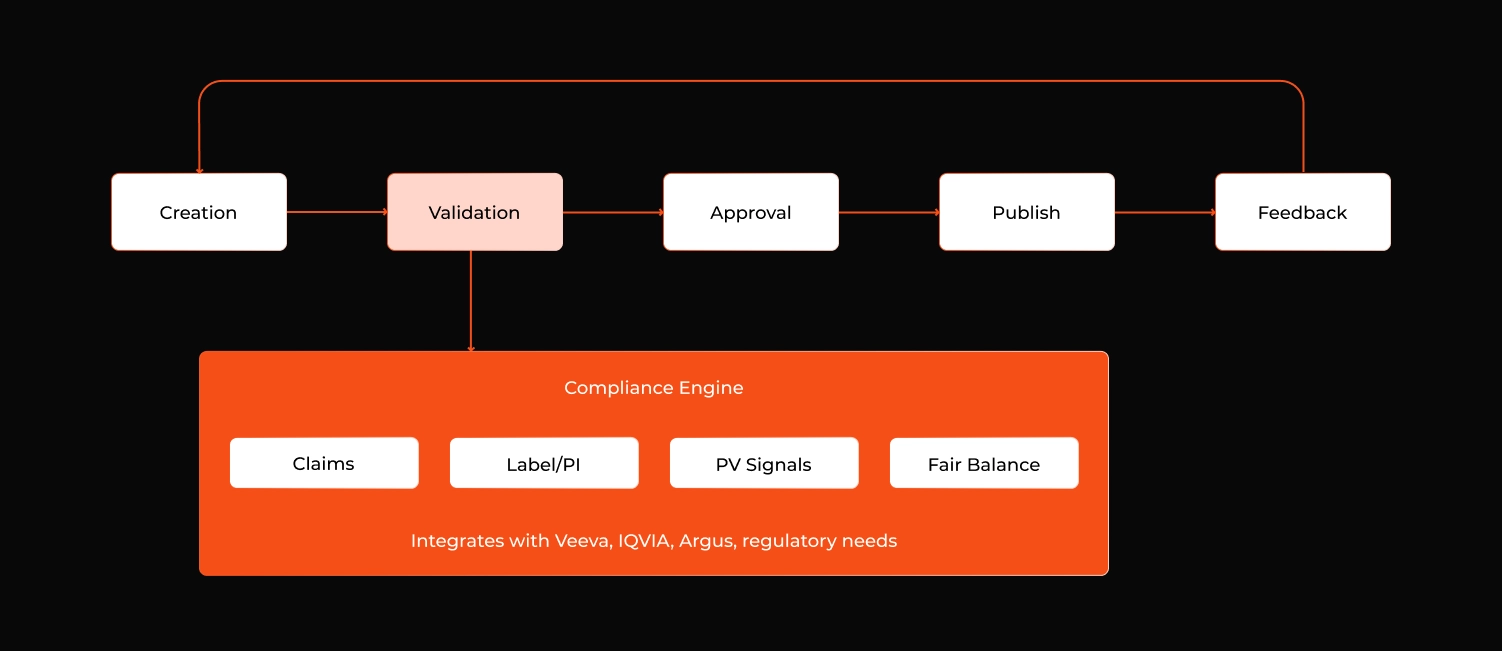
Figure 1: The engine sits inside step 2 of a typical content workflow. It doesn't replace MLR instead it hands the reviewer a pre-annotated asset; so the mechanical work is already done by the time human judgment is needed.
This article is a working blueprint for building that engine, written for engineering leaders and architects, and useful as a frame for the medical and regulatory leaders who'll sponsor it.
What "compliance" really means in pharma
A common mistake is to treat AI in pharma compliance as a single problem. It isn't. The engine has to serve at least four distinct surfaces:
1. Promotional content / MLR review. Claim-to-reference substantiation, label adherence, off-label detection, fair balance between efficacy and safety, channel and market rule compliance.
2. Medical affairs content. Scientific platforms, KOL communications, advisory boards, medical information letters, congress decks. Different audience, different rules, typically less restrictive than promotional, but with their own integrity standards and increasing regulatory scrutiny.
3. Pharmacovigilance signal detection. Adverse event mentions buried in promotional content, social listening output, customer feedback, and field communications have to be detected and routed into PV systems within strict reporting windows.
4. Regulatory submission support. Drafting, cross-checking, and traceability for variations, periodic safety updates, and post-marketing commitments.
A useful engine spans all four with shared infrastructure but specialized agents per surface. Treat them as one indistinct compliance problem and you end up with a generic GenAI tool that's shallow on every surface and deep on none.
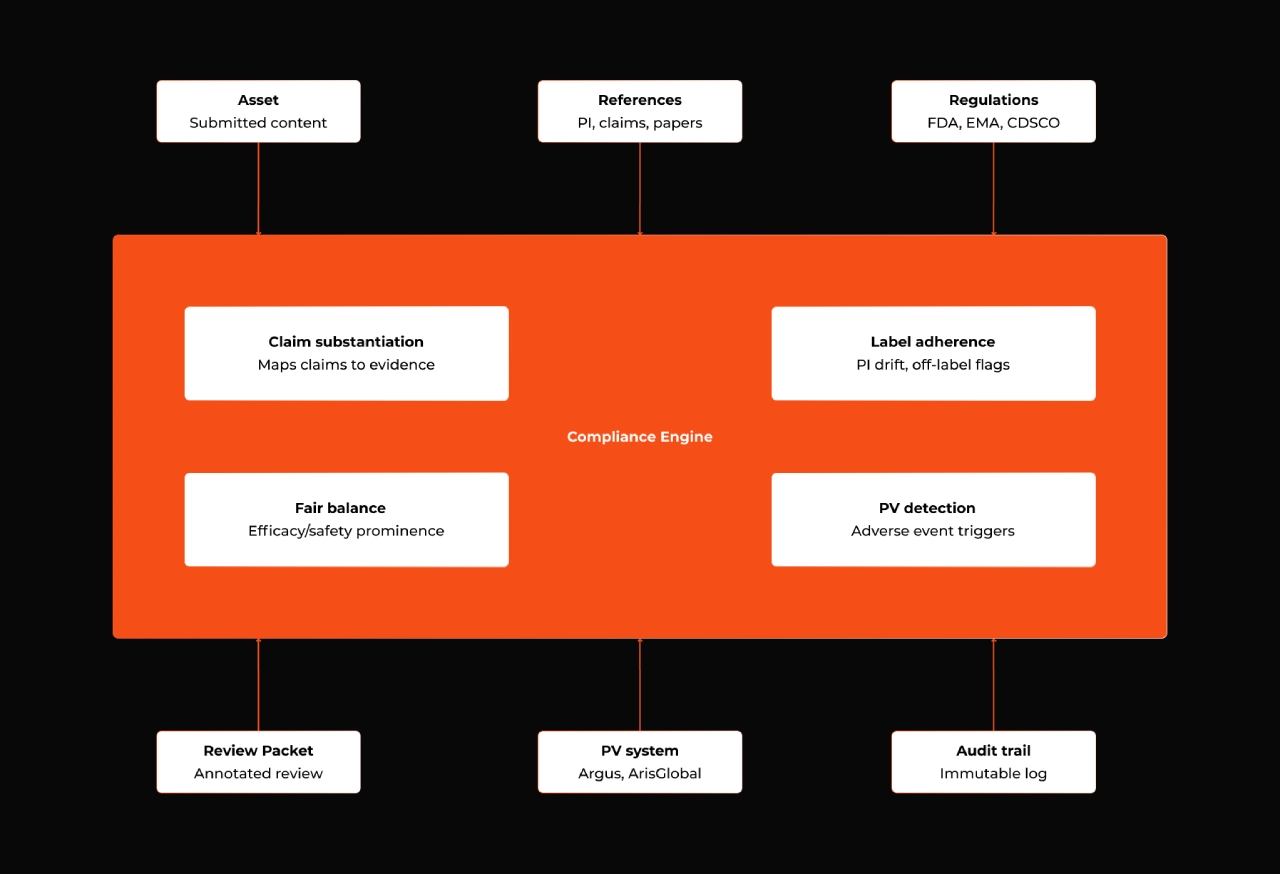
Figure 2: The engine at a glance — three input streams (assets, references, regulations), four capability areas, three output destinations into existing systems.
The Five Layers of Agentic AI Compliance Engine Architecture
Architecturally, you want this engine to be modular enough that each layer can be swapped without dragging the others along. We organize ours into five layers, roughly in the order data flows.
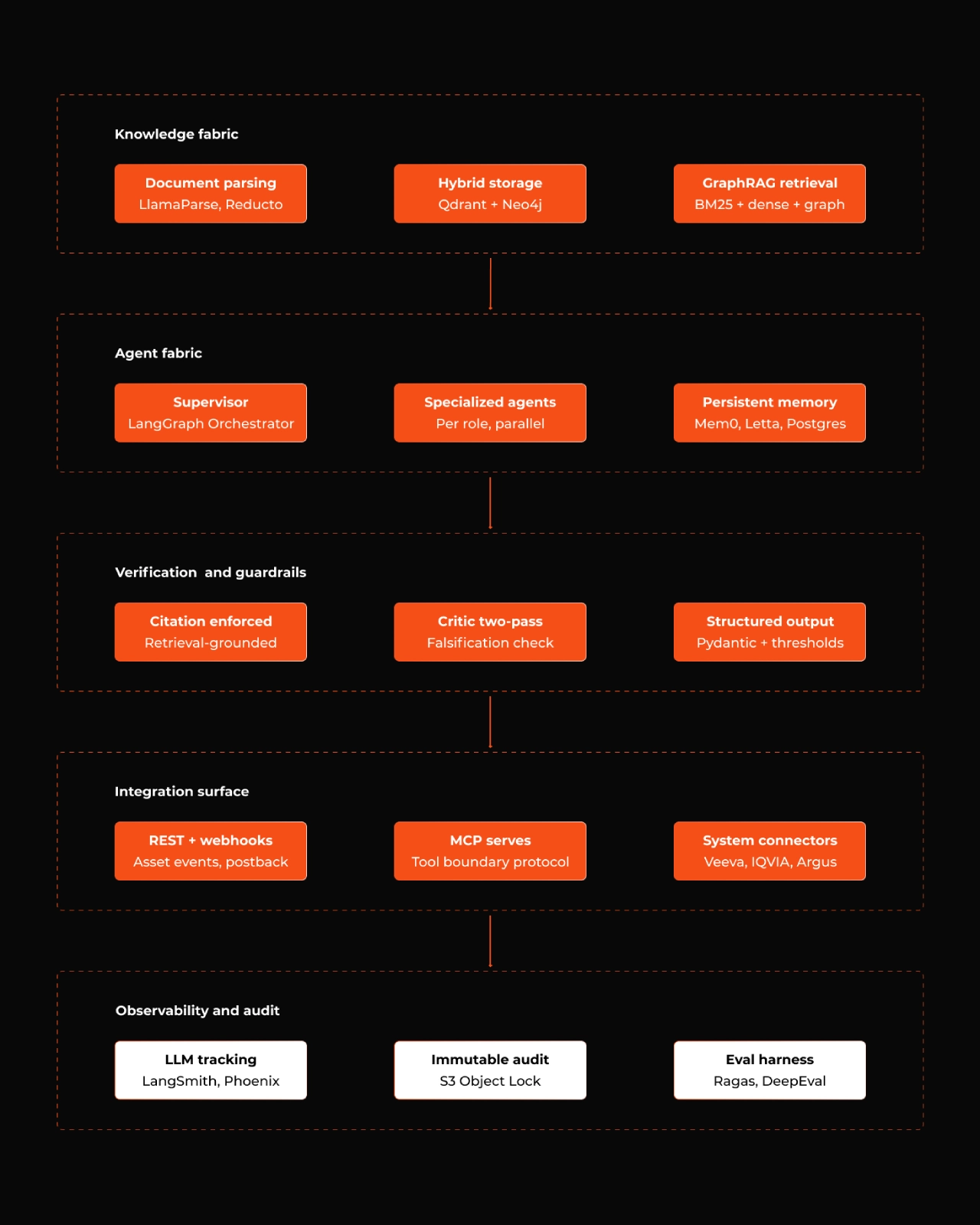
Figure 3: The five layers, with representative components in each. Observability and audit are rendered separately to signal that it cross-cuts every other layer.
Layer 1: Knowledge fabric
This is the data foundation. The engine ingests:
- The asset under review: text, images, video scripts, slide decks, email templates, web copy. Multimodal parsing matters more than people think; visual fair balance, the prominence of safety information in slide layouts, and text inside images all need extraction. Tools like Unstructured.io, LlamaParse, and Reducto are pragmatic here.
- The reference corpus: peer-reviewed publications, the current PI / label / Investigator's Brochure, the company's approved claims library, internal data on file, and the SOP and checklist documents that encode reviewer expectations.
- Regulatory feeds: FDA, EMA, MHRA, PMDA, CDSCO, and the relevant local market guidelines, polled and diffed continuously.
- Historical reviewer decisions: This last one is the most under-used asset in most pharma companies. Past MLR comments, approvals, rejections, and revisions tell the engine how this specific company's reviewers actually think — and that's what makes the engine progressively better, not just functional on day one.
Storage has to be hybrid. Vector retrieval over a chunked corpus (Qdrant, Weaviate, or pgvector) handles semantic recall. A graph store (Neo4j or Memgraph) handles the cross-references that flat retrieval misses - a clause in a market code referencing a label section referencing a clinical study referencing a regulator's guidance. GraphRAG works well here because compliance is densely cross-referential. In practice, hybrid retrieval (BM25 + dense vectors + graph traversal) outperforms any single method by a meaningful margin.
Layer 2: Agent fabric
The temptation is to write one big prompt and call it a day. Don't. AI in pharma compliance covers different kinds of judgment and lumping them together both reduces accuracy and makes failures impossible to debug.
The agent fabric specializes:
- A claim extraction agent that identifies every clinical, comparative, or quantitative claim in the asset.
- A substantiation agent that maps each claim to candidate references and scores semantic congruence; does the cited paper actually support this claim, in this population, at this dose, against this comparator?
- A label adherence and off-label agent that compares the asset against the current PI and flags drift.
- A fair balance agent that does structural and visual prominence analysis — text-to-safety ratios, hierarchy, slide timing.
- A PV trigger agent that detects adverse event language and routes it.
- A policy and channel agent that handles market guidelines, channel rules, ISI inclusion, accessibility.
Orchestrate with a supervisor pattern — LangGraph state machines with checkpointing, or the equivalent in OpenAI Agents SDK or AutoGen. The supervisor routes the asset through agents in parallel where it can, sequentially where dependencies require, and aggregates the findings.
Memory is where most engines either get good over time or stay flat forever. Short-term scratchpads handle within-asset reasoning. Long-term episodic memory (Mem0, Letta, or a thoughtful Postgres setup) holds the company's reviewer patterns, brand-specific exceptions, and the running history of decisions. Skip this layer and every asset starts the engine from scratch. Build it well and the engine measurably improves at predicting reviewer flags after a few months in production.
Layer 3: Verification and guardrails
In pharma, hallucinations aren't merely embarrassing. They can become regulatory findings. Three guardrails are non-negotiable:
- Citation enforcement. Every verdict must be retrieval-grounded. Structurally prevent the model from producing a finding without supporting evidence in the retrieved context. Don't ask nicely via a prompt; make it impossible at the framework level.
- Two-pass verification. A generator agent produces a finding. A separate critic agent — different model, sees only the finding plus retrieved evidence; tries to falsify it. Disagreement triggers human review.
- Confidence thresholds with mandatory abstention. Below threshold, the verdict is "unable to determine" and routes to a human queue. Most LLM systems are tuned to always answer. A compliance engine must be tuned to abstain.
Outputs are structured, not freeform. Use Pydantic schemas (or equivalent) for every finding, with mandatory fields for verdict, confidence, citations, and rationale. That's what makes the system auditable later.
Layer 4: Integration surface
A compliance engine that doesn't integrate is useless. It earns its keep by living inside the regulated content management and workflow systems the company already runs, so integration belongs in the design from day one.
The pattern that works in our experience: expose the engine as REST services, with Model Context Protocol (MCP) servers for clean tool boundaries when interacting with external systems, and webhook subscriptions for asset events from the host workflow. The engine receives an asset event from the regulated content management platform, pulls reference and label data through pre-built connectors, runs its agent pipeline, and posts findings back as structured annotations into the host platform's review interface. Reviewers work in the system they already know. The engine is invisible to them, except through better-prepared review packets.
For pharmacovigilance, the engine routes detected triggers into the PV system of record (Argus, ArisGlobal LifeSphere, or whatever's in place) through their respective APIs, preserving timestamp evidence for reporting compliance.
Layer 5: Observability and audit
- Observability is for the engineering team. Conventional LLM ops tooling does this: LangSmith, Langfuse, Arize Phoenix, Braintrust. Every LLM call, tool invocation, retrieval, and retry instrumented and queryable. Token costs, latency, and failure modes visible in real time.
- Audit is for the regulator, the inspector, and the client's compliance officer. Append-only, immutable logs with cryptographic chaining, capturing every retrieval, every verdict, every override, every human decision, with timestamps and identity. This is what makes the engine defensible if a finding is ever challenged. Cloud providers' immutable storage (S3 Object Lock, Azure immutable blob storage) is the practical foundation.
Evaluation runs continuously. Ragas and DeepEval for retrieval and generation quality. Custom eval harnesses for domain-specific decisions. Calibration tracking (when the engine says it's 85 percent confident, is it actually right 85 percent of the time?) is reported monthly.
Runtime: what happens to one asset
Concretely, here's how a single HCP detail aid moves through the agentic AI compliance engine.
- A brand team submits the asset to the regulated content management platform. The platform fires an event. The engine receives it, pulls the asset and the relevant product's PI, claims library, and reference corpus into its working context. The supervisor dispatches the claim extractor first, then runs substantiation, label adherence, fair balance, PV detection, and channel rule checks in parallel.
- Each finding is logged with citations and confidence. The verification critic runs a second pass on every high-impact finding. Anything below confidence threshold is flagged for human-only resolution. The aggregated review packet; every claim mapped to references, every potential issue annotated with rationale and citation, every PV trigger surfaced and routed; is posted back into the host platform as an annotated layer over the original asset.
- The MLR reviewer opens the asset in the platform they already use. The slow, repetitive work is done. Their job is to confirm, override, or escalate; not to find issues from scratch. Their decisions flow into the host platform's audit trail. The engine learns from them. The next similar asset goes through faster, with higher first-pass agreement between engine and reviewer.
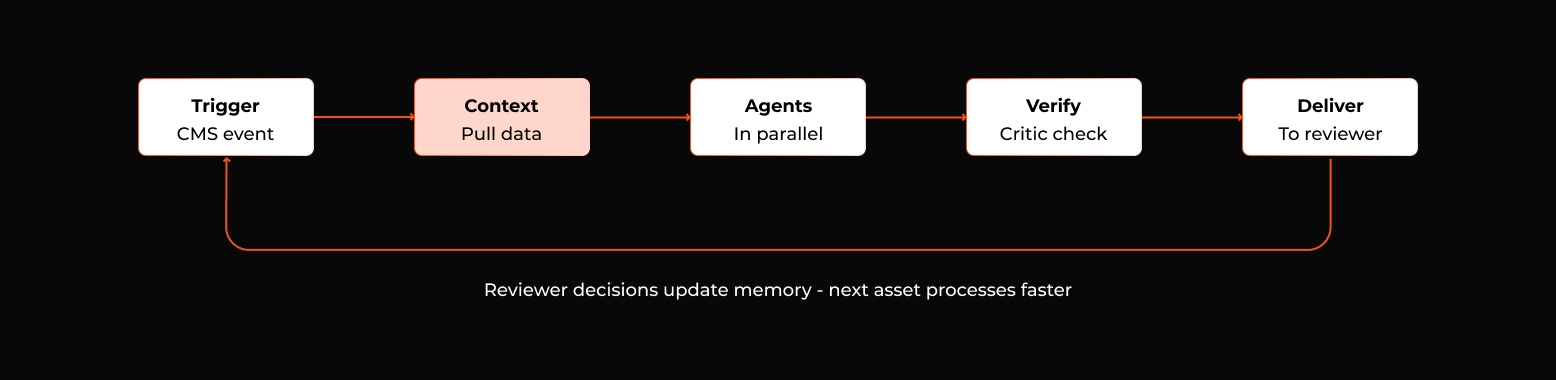
Figure 4: The runtime path for one asset. Reviewer decisions at the end loop back into memory, so the next similar asset starts the engine in a smarter state.
Integration is the moat
Most large pharma and biotech companies already operate on Veeva, IQVIA, Aprimo, Adobe Experience Manager, or some custom workflow built on SharePoint. The right agentic AI compliance engine integrates with all of them and tries to compete with none. The differentiation isn't the agent itself because agentic patterns are commoditizing fast. It's the integration depth, the domain calibration, and how the team delivers.
In the work we've done with life sciences clients at Syren, three things have consistently determined whether a compliance engine ships and creates value or stalls in pilot:
- A hybrid integration approach that meets the client's existing regulated content management and PV systems where they are, instead of asking them to migrate.
- A delivery model that puts engineering and domain expertise on the same team from day one. Not engineering builds, then domain reviews it at the end.
- Calibration and feedback instrumented from day one and reported every month. The reviewer's first-pass agreement with the engine is the metric that matters, and it's the metric that justifies expanding scope later.
Responsible Deployment
Version 1 - A compliance engine should be a decision-support system, not a decision-making one. Reviewers retain final authority. Irreversible actions (filings, publications, releases) require human approval. Audit trails are immutable and exportable. The engine's outputs feed into the client's existing validated workflow system, which remains the system of record. It keeps the engine outside the heaviest validation burden under 21 CFR Part 11, EU Annex 11, and equivalent frameworks, because the engine is providing input to a validated system rather than itself being the system of record.
Version 2 - Expanded autonomy can happen once you have months of calibration data to back them.
Data security follows the same methodology: client-specific deployment in approved cloud regions, no model training on client data, certifications aligned with the client's expectations (ISO 27001, SOC 2 Type II, HIPAA, GDPR, India's DPDP Act, and whatever else the contract specifies).
Closing
The pharma compliance bottleneck won't clear itself. Content volume keeps rising, reviewer headcount doesn't, and the regulatory surface keeps expanding. A well-built compliance engine, which is agentic, integrated, calibrated, and auditable is the most direct way to compress cycle times without compromising the rigor that makes the work worth doing in the first place.
Whether the engine ships or stalls in pilot has less to do with the AI and more with the below three:
- how tightly it integrates with the host workflow
- how well it's calibrated to this client's reviewer patterns
- and whether the team can debug it when something goes wrong
If you're scoping a compliance engine for your content and regulatory operations, talk to an expert at Syren. We've done this integration work before, and we're happy to share what we've learned.


