
As machine learning becomes embedded in core business systems, data science teams are focusing less on building models and more on managing how those models perform, evolve, and scale reliably in production.
Databricks MLOps introduces automation, reusability, reproducibility, and governance into model development. It moves teams away from isolated experiments toward repeatable, production-grade workflows. It ensures models remain stable even as data, infrastructure, and objectives evolve.
On Databricks, the MLOps stack for general-purpose ML and for GenAI/LLMs shares many foundational components but also has key differences in specialized tools and practices. The Databricks MLOps stack for GenAI/LLMs, often called LLMOps, is an extension of MLOps that incorporates components from Mosaic AI to handle the fine-tuning, vector search, and agent orchestration for generative workloads.
Databricks MLOps Stack
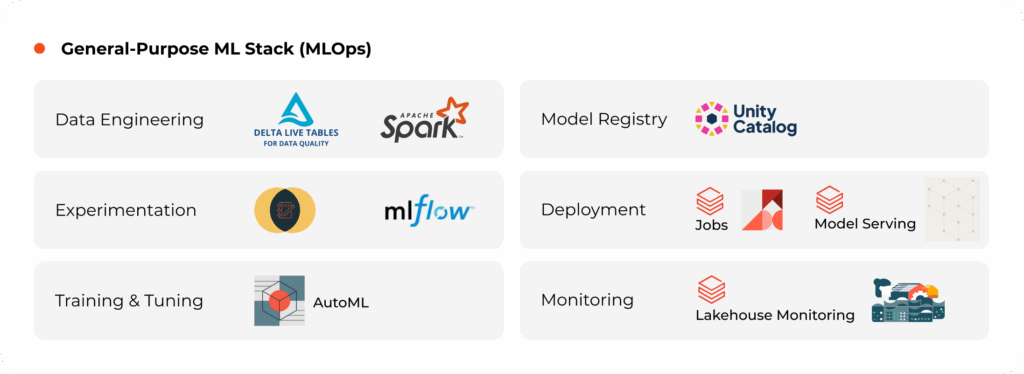
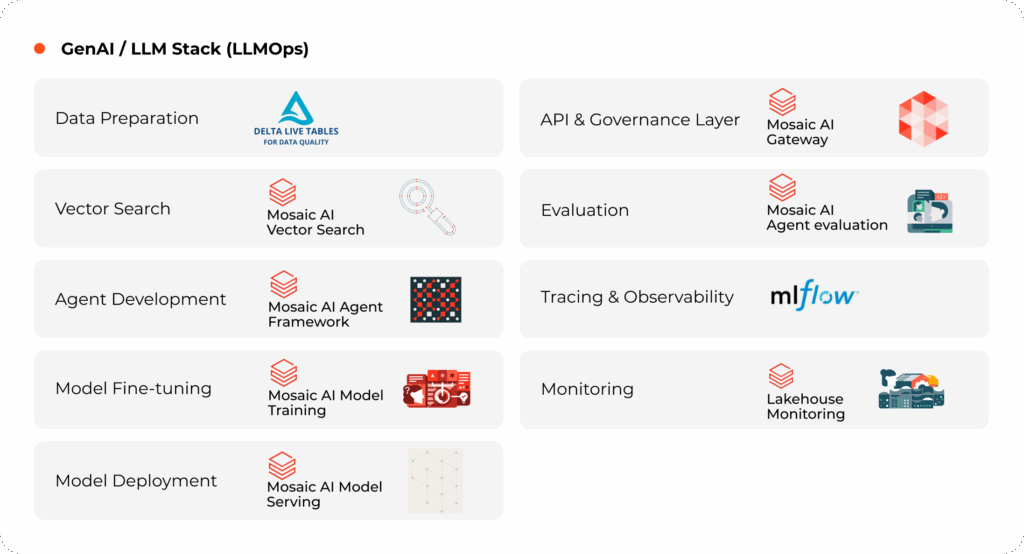
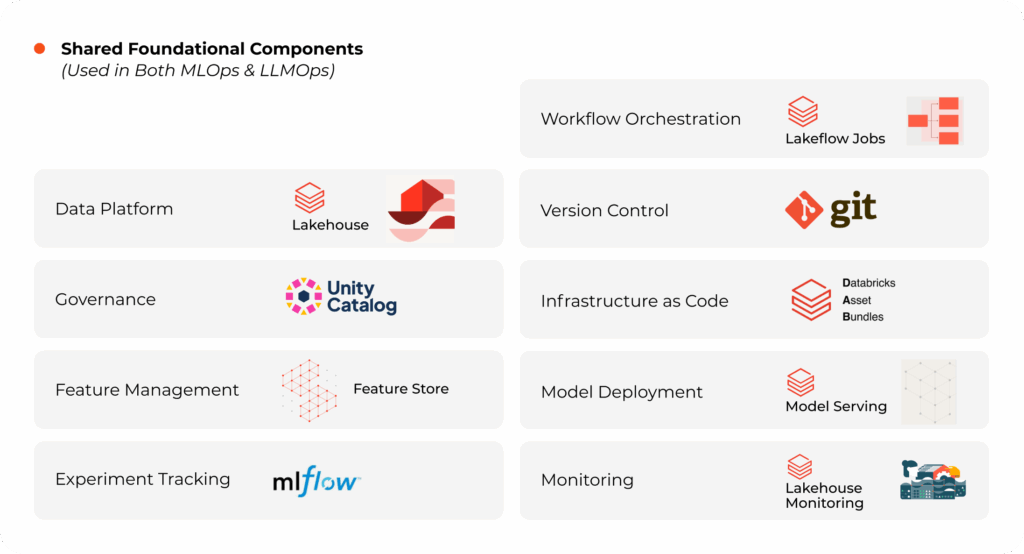
MLOps on Databricks
As machine learning initiatives scale across teams, projects, and environments, organizations need a unified Databricks MLOps approach that ensures consistency, traceability, and automation. Databricks enables this through its Lakehouse Platform, powered by Databricks ML flow, Delta Lake, Unity Catalog, and Databricks Asset Bundles (DAB), to operationalize ML and GenAI workloads at enterprise scale while optimizing both CapEx and OpEx.
1. General-Purpose MLOps on Databricks
Collaboration, Traceability, and Governance
MLflow Tracking & Model Registry
Databricks ML flow automatically logs parameters, metrics, and artifacts from every experiment. The integrated Model Registry supports versioning, approval workflows, and rollbacks, allowing teams to safely promote the best-performing models into production.
Delta Lake for Data Lineage
With immutable data snapshots and versioned tables, Delta Lake ensures every dataset used for training or inference is auditable and reproducible. This strengthens compliance, debugging, and experiment reproducibility.
Databricks Asset Bundles (DAB)
DAB brings Infrastructure-as-Code (IaC) principles to MLOps. By defining environments declaratively, it standardizes deployments across dev, test, and prod workspaces, reducing configuration drift and enabling consistent CI/CD automation through Databricks Workflows.
Together, these components foster collaboration, prevent duplication, and create a governed foundation for scalable Databricks MLOps best practices across the enterprise.
Observability, Monitoring, and Drift Management
Telemetry Instrumentation
Collect real-time inference metrics (latency, accuracy, feature distributions, resource utilization) using Prometheus, Grafana, or Azure Monitor.
Evaluation Registry and Auditability
Each evaluation run should log metrics and artifacts to Databricks ML flow Tracking and persist metadata to a Delta table acting as an evaluation registry.
Data Quality Validation
Integration with Great Expectations, Soda, or Deequ to validate incoming data before retraining or inference.
Explainability & Bias Detection
Pre-production gates can integrate explainability and fairness checks using SHAP, LIME, and Fairlearn, promoting trust and transparency in ML models.
CapEx Optimization — From Fixed Assets to Elastic Compute
Ephemeral Compute Clusters
Databricks MLOps framework automates cluster spin-up and termination, provisioning GPU/CPU only when needed. This elasticity minimizes idle resources and reduces infrastructure lock-in.
Impact: Up to 40% reduction in capital expenditure through on-demand, right-sized compute.
Containerization & Environment Reuse
In Databricks MLOps, runtime environments standardize dependencies across teams, ensuring reproducibility and eliminating redundant setup for experimentation or staging.
Centralized Feature and Model Registries
The Databricks Feature Store and MLflow Model Registry promote reuse, reduce redundant model training, and streamline governance through unified metadata and lineage.
Impact: 20–30% savings from reduced duplication and optimized storage.
OpEx Efficiency — Automating the ML Factory
End-to-End Pipeline Automation
Databricks Workflows orchestrate the complete ML lifecycle, from data preparation and model training to validation, deployment, and rollback, reducing manual effort and operational risk.
Impact: Teams manage up to 10× more models with the same resources.
FinOps & Cost Observability
Built-in telemetry dashboards monitor DBU utilization, cluster efficiency, and GPU consumption. Cost attribution by workspace, project, or team helps optimize resource usage.
Impact: 15–30% reduction in operational spend via transparent cost control.
Intelligent Retraining & Artifact Reuse
Retraining is automatically triggered only when drift thresholds are exceeded. Cached datasets, feature tables, and model artifacts reduce redundant compute cycles.
Governance and Audit Automation
Unity Catalog enforces role-based access control (RBAC), lineage tracking, and policy-as-code validations. Automated audit trails streamline compliance for ISO, SOC2, and GDPR.
Impact: 40–60% reduction in compliance and audit overhead.
Incident Prevention & Faster Recovery
Proactive anomaly detection, telemetry alerts, and rollback capabilities minimize downtime and accelerate issue recovery.
Impact: 60–80% faster MTTR (Mean Time to Recovery).
Security, Compliance & Governance
Enterprise-scale Databricks MLOps demands secure promotion and regulatory alignment. Databricks integrates these capabilities at every layer.
Secure Model Promotion
Governed model registries with approval workflows and RBAC via Unity Catalog ensure safe and auditable deployments.
Data Governance
Integrated lineage and access control align with data catalogs such as Purview or Collibra for PII masking and GDPR/HIPAA compliance.
Audit Trails
Every model, dataset, and job is logged with hashes and metadata for complete traceability.
Lineage Enforcement with Unity Catalog
Unity Catalog captures lineage across notebooks, jobs, and workflows—tracing models back to the exact Delta version and transformation code used.
Reliability and Scalability
Databricks MLOps ensures consistent reliability under real-world workloads with a fault-tolerant design and elastic scaling.
Batch vs. Real-Time Workloads
Use Delta Live Tables or Structured Streaming for real-time ingestion, while batch pipelines run on dedicated job clusters to maintain predictable performance.
Cluster Capacity Planning
Autoscaling and workload isolation enable efficient handling of retraining bursts or large inference runs while maintaining predictable costs.
Fault-Tolerant Pipelines
Databricks Workflows support checkpointing, retries, and transactional writes for resilient orchestration of long-running or data-intensive jobs.
Unified Monitoring
Lakehouse Monitoring and MLflow Metrics consolidate model, data, and pipeline health in a single observability layer.
2. GenAI and LLM MLOps on Databricks
As enterprises extend into Generative AI, Databricks MLOps provides a unified foundation for managing LLM training, fine-tuning, evaluation, and inference — all within the same Lakehouse architecture. This ensures consistent governance, reproducibility, and performance across GPU-intensive workloads.
LLM Workflow on Databricks
| Stage | Objective | Key Components | Examples |
|---|---|---|---|
| Data Ingestion | Stream or batch unstructured data | Auto Loader, Delta Live Tables, Structured Streaming | PDFs, documents, APIs |
| Data Processing & Vectorization | Text cleaning, chunking, and embedding generation | PySpark, Delta Tables, Vector Search | Knowledge-base embeddings |
| Model Training / Fine-Tuning | Fine-tune base models or train adapters | Mosaic AI, MLflow, LoRA | Domain-specific LLMs |
| Evaluation & Registry | Track metrics like hallucination rate, token cost | MLflow Metrics, Unity Catalog | Continuous evaluation and traceability |
| Deployment & Serving | Low-latency chat or RAG inference | Databricks Model Serving, Vector Search | Conversational assistants, intelligent search |
LLM-Specific Observability and FinOps
Telemetry & Token Cost Tracking
Databricks Lakehouse Monitoring extends observability to token-level metrics — including GPU utilization, latency, and cost per response — to manage resource efficiency.
Model Evaluation Metrics
LLM evaluation integrates with MLflow to track hallucination rate, context relevance, response quality, and safety filter triggers, ensuring controlled, high-quality model behavior.
Cost Optimization
Databricks’ auto-scaling GPU clusters and Mosaic AI training optimizations (mixed-precision training, parameter-efficient tuning) help manage GPU costs while maintaining performance.
Deployment Governance
Every endpoint, RAG pipeline, and adapter is registered in Unity Catalog, ensuring lineage, reproducibility, and secure access control across production environments.
Unified Impact Across ML and GenAI
By bringing traditional ML and GenAI pipelines into one governed environment, Databricks enables organizations to:
- Manage costs predictably through elastic compute and FinOps telemetry.
- Scale batch and real-time inference with fault-tolerant orchestration.
- Ensure governance and compliance across structured and unstructured data.
- Accelerate innovation through automation, reuse, and continuous retraining.
The result is a single, unified ecosystem that operationalizes both ML and LLM workflows, combining governance, scalability, and cost efficiency to power the next generation of enterprise AI.
How We Did It | Syren + Databricks
A leading FMCG enterprise was running over 30 forecasting models manually across multiple product categories and regional clusters every month. Each notebook was executed independently, creating challenges around scalability, reproducibility, and environment consistency.
The objective was to build a fully automated batch-oriented Databricks MLOps architecture that would reduce manual effort, enable seamless deployments across environments, and establish strong model governance within Databricks.
Solution Delivered
Syren implemented a batch-oriented Databricks MLOps framework integrating Databricks ML flow, Azure DevOps, and Databricks Asset Bundles (DAB) for orchestration, monitoring, and CI/CD automation. The design unified forecasting pipelines under a single, governed, and reproducible environment.
| Layer | Implementation |
|---|---|
| Data Ingestion & Processing | Monthly batch ingestion via Auto Loader into Bronze Delta tables, with PySpark/SQL transformations across the Medallion architecture (Bronze → Silver → Gold). |
| Feature Engineering | Offline feature computation and registration through Databricks Feature Store, ensuring reusability across models. |
| Model Training & Scoring | Scheduled batch workflows for distributed model training (XGBoost/scikit-learn) and bulk inference; outputs written to Gold Delta tables for consumption in Power BI. |
| Model Registry & Governance | Versioning, approval workflows, and lineage are maintained using Databricks ML flow integrated with Unity Catalog. |
| Automation & IaC | Environment provisioning and configuration are automated using DAB, enabling reproducible deployment across environments. |
| CI/CD Integration | Code versioning and pipeline automation via Azure DevOps; DAB bundles triggered for promotion from Dev → Test → Prod. |
| Monitoring & Drift Detection | Batch evaluation via Databricks MLflow metrics and PSI-based drift monitoring through Lakehouse Monitoring; retraining triggered automatically on threshold breach. |
| Observability & FinOps | Telemetry dashboards tracked DBU utilization, cluster cost, and per-model efficiency for transparent FinOps governance. |
Syren Differentiators
- Business-Aligned Value: Forecast accuracy, OTIF, and inventory turns are defined as measurable KPIs driving the automation scope.
- Architecture Excellence: Lakehouse-native, metadata-driven ingestion and transformation aligned to demand and inventory domains.
- AI/ML Operationalization: Automated retraining and batch deployment pipelines reduced manual runs by 100%.
- Engineering & Ops Maturity: Databricks-native orchestration (Workflows, DAB, MLflow) ensures resilient, governed, and monitored deployments.
- Accelerator-Driven Delivery: Syren’s IngestX, DQX, and FinOps telemetry packs shortened delivery cycles and ensured cost visibility.
Impact
- Effort Reduction: Fully automated monthly forecasts, no manual notebook runs.
- Speed: Forecast generation time reduced from days to hours.
- Scalability: Framework supports 30+ models across multiple product-location combinations.
- Governance: End-to-end lineage, automated deployment, and environment consistency via Unity Catalog and DAB.
- Cost Efficiency: ~25% operational savings through optimized cluster utilization and FinOps observability.
Conclusion
As data science matures within enterprises, the emphasis will increasingly shift toward observability, drift management, and automated retraining, ensuring models stay aligned with real-world behavior. Databricks MLOps brings automation, observability, and cost efficiency together, helping teams optimize both CapEx and OpEx while maintaining performance at scale.
By promoting reusability and automation, Databricks MLOps helps organizations optimize both CapEx and OpEx, making machine learning not just reliable and scalable, but also economically sustainable across the enterprise.
At Syren, we see Databricks MLOps as the backbone that turns machine learning into a sustainable, enterprise-ready capability.


