
The problem with static journey plans
Distribution driven businesses cement, FMCG, pharmaceutical, building materials, agricultural inputs run their field sales operations on Journey Cycle Plans. Central planning teams set fixed dealer visit schedules weeks in advance of the cycle. Since the cycle goes live, reality has already moved on. A high value dealer has gone to dormant. A new construction project has surfaced inside the sales officer's catchment, creating fresh demand. One of the officer's top three dealers has been targeted by a competitor with a counter scheme. None of this gets into the plan.
The Sales Officer in the field knows the plan is outdated. The Area Sales Manager knows. The Regional Sales Manager knows. But the next planning cycle is two weeks away.
Syren Sales Journey AI breaks this cycle. The platform re-scores every dealer roughly once a day using AI. Sales officers execute the plan through a mobile field application. Every check in, override, and order closes back into the lakehouse for continuous learning. The architecture is built natively on Databricks, with Lakebase as the operational backbone.
How the lakehouse pipeline scores dealers every day
Behind the field app is a Databricks Lakeflow Declarative Pipeline that turns raw operational data into actionable visit priorities. The flow follows the medallion architecture, all governed end to end by Unity Catalog.
Bronze ingests all source data dealers, sales officers, sales, visits, targets, payments via Auto Loader from ADLS landing zones. New files are picked up incrementally with full provenance, no custom orchestration.
Silver turns raw data into trustworthy data. Master entities are stored as SCD Type 2 using DLT's apply_changes when a dealer's class changes, the old version is timestamped and a new active row is inserted, preserving complete history. Transactional tables flow as streaming validations where data quality rules are enforced declaratively, surfacing patterns like sub-10-minute visits for ASM coaching rather than silently dropping them.
Gold turns validated data into business-ready outputs: a 360-degree dealer view, a Visit Priority Score decomposed into four explainable components (Performance, Demand, Coverage, Risk) traceable to BRD rules, the SO daily plan with reasons attached, and the regional rollup feeding the RSM heat-map. Every Gold table is one declarative query away from production.
The whole pipeline runs in under five minutes, end to end with Photon. Data quality metrics surface automatically in the DLT UI. Lineage is auto captured by Unity Catalog. No external monitoring stack required.
Why Lakebase, not Delta?
Delta is an outstanding platform for analytics. You can read a million rows at once, run aggregations, and build dashboards. But the workload on a mobile field app is fundamentally different. A sales officer checking in needs a single row to write to succeed in under 200 milliseconds while standing at the dealer counter. A credit check on order entry must be completed in under 100 milliseconds. Delta is purpose built for scanning billions of rows; it is overkill for reading a single one.
Lakebase fills this gap. It is managed Postgres inside the Databricks workspace, sharing the same Unity Catalog and audit trails as Delta, but with OLTP performance and latency equivalent to operational Postgres.
In Syren Sales Journey AI, four operational flows write directly to Lakebase:
- Visit check ins. When the sales officer taps "Check In" on a dealer card, geo coordinates, timestamp, dealer ID, and officer ID land in a Lakebase visit_checkins table in one round trip. The Flask backend authenticates via Databricks OAuth. A short lived database credential is generated at runtime by the Databricks SDK, cached for 50 minutes, and refreshed before expiry. The check in row carries the geo validity flag (within 100m of registered dealer geocode) and duration status, both evaluated in Lakebase, not Delta.
- Plan overrides. When an officer overrides the system's recommendation, the override lands in Lakebase with a reason code from a controlled vocabulary. An ASM is notified, the approval workflow runs against live transactional rows, and approved overrides feed back into the next day's plan.
- Dealer orders. Credit policy rules execute against Lakebase tables 60 day overdue threshold, blocked dealer status, available credit. The decision returns to the tablet in under 100ms.1
- Live KPI ticker. The app's header polls Lakebase every 5 seconds for "Check ins today: 47 · Active officers: 89 · Avg interval 22m". The same query against Delta would take 1 3 seconds; against Lakebase it returns in under 50ms.
The Lakehouse Sync advantage
Lakebase's automatic sync to Delta is what makes this architecture work without painful integration. Every table we write to in Lakebase replicates to Unity Catalog as a Delta table within 1-3 minutes. No Kafka. No Fivetran. No custom CDC pipelines.
The visit check in that lands in Postgres for the officer's real time UX is the same row the next morning's pipeline reads from Delta to recompute the dealer's priority score. One write, two consumers, zero glue code. For data engineers used to maintaining brittle Postgres to Delta CDC pipelines, this alone is worth the migration.
The killer feature: branch in two seconds
Where Lakebase becomes genuinely unique is branching. Regional sales managers run what if simulations constantly.
- What happens to my territory if 20% of my mid tier dealers go dormant during monsoon?
- What if a competitor drops their flagship price by 4% in a key market?
- What if I shift visit cadence from 7 days to 10 days for top tier accounts?
Traditionally this means duplicating data into a separate sandbox, running scenarios, then reconciling back. Painful, expensive, slow.
With Syren Sales Journey AI, an RSM toggles "Scenario Mode" from the HO What If panel. A new Scenario Branch for the current date is created in under two seconds. Every write made by the RSM lands on the new branch, not on the live production database. The RSM runs what if analyses, compares results against live, then either clicks "Discard" to delete the branch or "Promote" to merge the results back into production.
The HO What If panel surfaces this as live sliders beat size change, new SKUs introduced, competitor pressure, visit cap per SO per day. Each slider movement triggers a recompute against a Databricks SQL endpoint backed by an uplift model registered in the Unity Catalog Model Registry. Primary sales uplift, productive call uplift, and DSO change refresh in real time. The same zero copy branching concept that changed source code versioning with Git is what changes operational data versioning here.
Five persona views, one app, one governance plane
Syren Sales Journey AI ships as a Databricks App a Flask service deployed inside the workspace, sharing the same identity, network, and audit boundary as the data it consumes. Each persona gets a tab tuned to their decision rhythm:
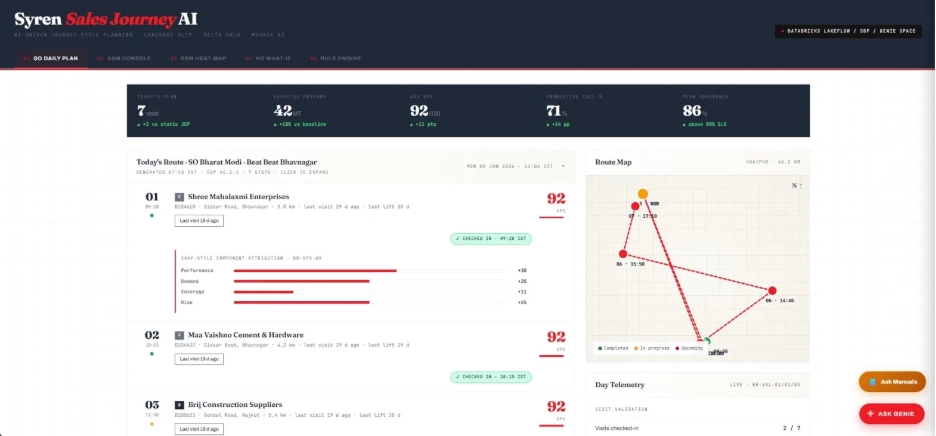
SO Daily Plan
The sales officer sees today's seven prioritized visits with a route map, VPS score, SHAP style component attribution (Performance, Demand, Coverage, Risk), and live day telemetry visits checked in, geo validity, duration compliance. Every reason chip is auditable. "Last visit 19 d ago", "Overdue 62 d · BR RSK 01", "Festival window +10 d". Three reasons per dealer, automatically generated from the rule engine.
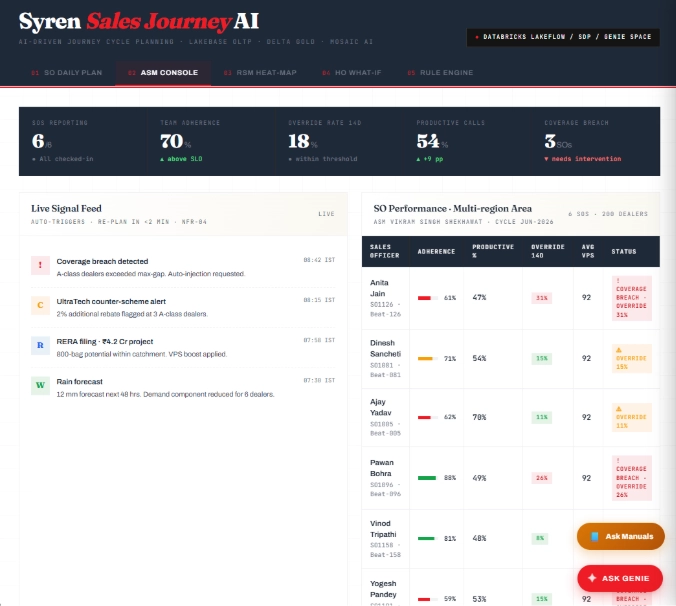
ASM Console
The area manager sees a live signal feed coverage breaches, competitor schemes, RERA filings, rain forecasts and a performance table for every SO under their span. Override rate above 25%, adherence below 60%, coverage breaches on A class dealers all surface as status flags. The data quality dashboard for the JCP itself.
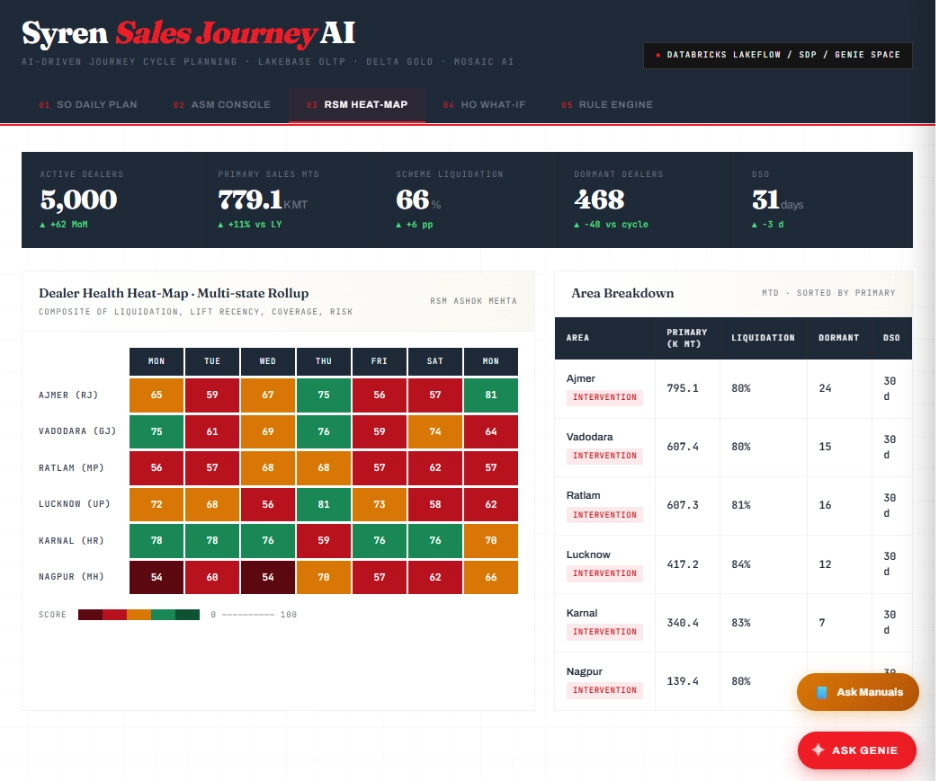
RSM Heat Map
The regional manager sees dealer health across six areas and seven days as a colour coded grid (45 95 health score scale), with an area breakdown table sorted by primary sales. Intervention zones jump out immediately.
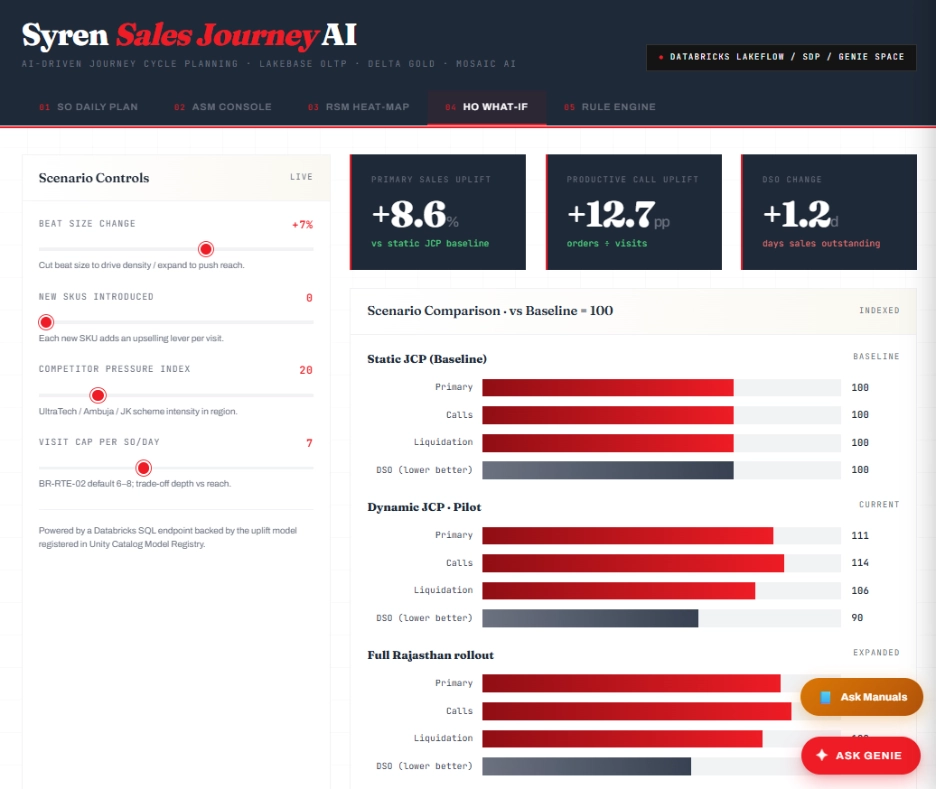
HO What If
Four live sliders feeding an uplift model registered in Unity Catalog. Indexed scenario comparison against the static JCP baseline of 100.
Rule Engine
Every business rule from the BRD codified, categorised, weighted, version controlled in Unity Catalog. VPS scoring rules, coverage norms, validation thresholds, risk triggers, override gates. Sixteen rules visible in one table. Audit ready.
Two Mosaic AI surfaces, one governance plane
Syren has two Mosaic AI interfaces incorporated directly into the platform.
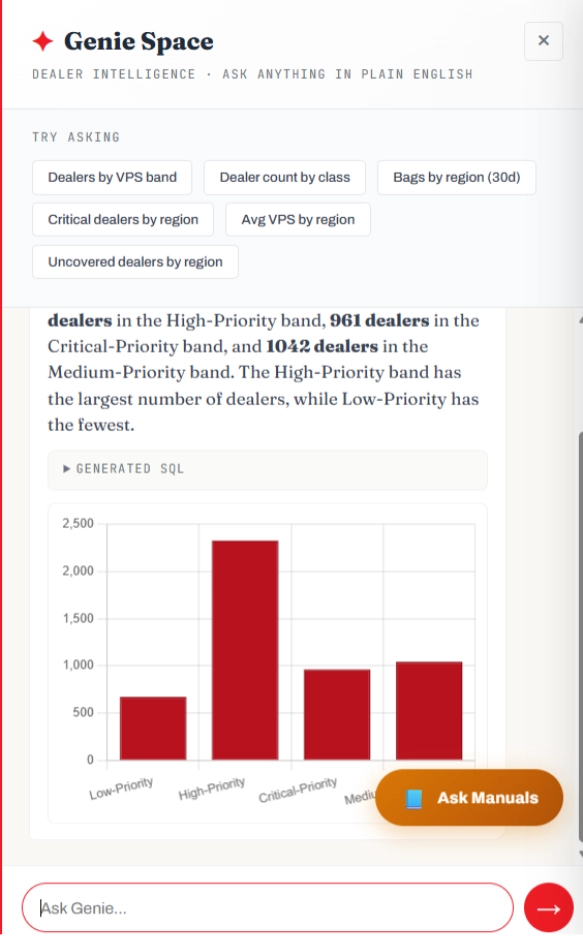
Ask Genie lets sales officers and managers query the lakehouse in natural language. The Genie panel accepts questions like "How many dealers are in each VPS band?", "What is the average VPS score by region?", or "How many dealers have not been visited in over 20 days, grouped by region?". Genie translates each question to SQL against the Gold tables, executes against the same SQL Warehouse the app uses, and returns the answer inline text, generated SQL (collapsible), tabular result, and a bar chart when the shape fits. Follow up questions maintain conversation context. Zero training. Zero hand holding. Just the right answer, governed.
Ask Manuals uses a Databricks Knowledge Assistant RAG over field manuals, SOPs, scheme guides, and competitor comparisons stored in Unity Catalog Volumes. When a contractor asks "why is your PPC more expensive than UltraTech?", the officer queries Ask Manuals on their tablet and gets a structured price defence talk track in seconds, with the source manual cited. The assistant is exposed as a serving endpoint and called from the Flask backend.
Both surfaces sit on the same governed UC catalog as the operational data. Access control, lineage, audit unified. The data the officer queries through natural language is the same data the pipeline produces and the dashboard renders. One catalog, one permission model, three modalities.
Why this stack was the right call
Building this on Databricks meant we did not assemble eight things from eight vendors. Auto Loader handled ingestion. Lakeflow Declarative Pipelines handled transformation with data quality and SCD2 built in. Unity Catalog handled lineage and governance without writing custom code. MLflow handled the model lifecycle. Genie and Knowledge Assistant handled the GenAI surfaces. Databricks Apps handled deployment with managed identity. Lakebase handled the operational tier with zero glue Delta sync.
The boundary between operational and analytical workloads the line that has historically forced teams to choose Postgres OR lakehouse, then build painful integration between them has effectively disappeared.
Where Syren Sales Journey AI fits
The solution is industry agnostic across any field sales distribution model with a three tier hierarchy: manufacturer → dealer/distributor → retailer/contractor. We see strong fit in:
- Cement and building materials, where dealer relationships drive 70 80% of sales volume
- FMCG, where store level execution determines shelf share
- Pharma, where medical representative coverage compliance is regulatory
- Agri inputs, where seasonal dynamics make static plans particularly costly
- Industrial distribution generally, where field force productivity is the lever
Early access deployments are running in cement and one adjacent distribution segment, with additional customers onboarding in Q3 FY27.
Expected outcomes
Across early access customers we are seeing:
- Double digit lift in productive call rate (calls resulting in an order or material commitment)
- High single digit to low double digit primary sales lift in dynamic journey territories versus control
- Material reduction in plan override requests, because the AI ranking catches what officers would have manually overridden
- Tighter DSO driven by credit policy enforcement at order entry
Specific numbers vary by deployment and are shared under NDA with customer attribution.
What's next
We are scaling the early access cohort through Q3 FY27 and opening Syren Sales Journey AI to additional customers in cement, FMCG, and pharma distribution. The roadmap extends the platform with reverse ETL patterns for credit policy updates, an admin UI for scheme management, and additional Mosaic AI agents for specialised field tasks.
For Databricks customers exploring how to bring operational systems into the lakehouse without a forklift migration, Lakebase is the bridge. It is Postgres where you need it and lakehouse where you need it, and the boundary between them has effectively disappeared.


